
Sin dalla prima lezione è stato chiarito che l'accezione NoSQL non implica un rifiuto di SQL, e infatti alcuni DBMS di questo genere ne fanno uso, spesso in modo non esclusivo, affiancandogli altre modalità di interfacciamento. In questa lezione, inizieremo ad esplorare l'implementazione di SQL che è possibile utilizzare con OrientDB.
Caratteristiche di SQL su OrientDB
In OrientDB è stato scelto di implementare una versione di SQL molto simile a quella tradizionale. Ciò dovrebbe aiutare chi si avvicina per la prima volta a questo DBMS e che - come spesso capita - è abituato a lavorare su database relazionali.
Esistono comunque molte differenze con l'SQL tradizionale.
La più evidente è che i tradizionali JOIN tra tabelle, fulcro dei sistemi relazionali, non esistono più in OrientDB.
Quest'ultimo, ispirando la propria organizzazione dei dati ad un modello a oggetti, utilizza dei collegamenti detti links tra le varie entità. Ciò non creerà più una relazione tra informazioni, ma permetterà una vera e propria navigazione all'interno del sistema informativo snellendo, oltre tutto, la sintassi.
Altra differenza è la non obbligatorietà della proiezione nelle query. Mentre su SQL tradizionale una query veniva eseguita con una forma simile a:
SELECT * FROM ...dove si poteva sostituire all'asterisco l'elenco dei campi da proiettare, in OrientDB vedremo forme come la seguente:
SELECT FROM ...
Inoltre in OrientDB non troveremo più la clasusola HAVING, rimpiazzata da un meccanismo di subquery, e nemmeno DISTINCT, che in questo DBMS diverrà una funzione invocata come segue:
SELECT DISTINCT(reparto) FROM ...Questi ed altri aspetti verranno approfonditi nel corso delle prossime lezioni, mentre nel prosieguo di questa presenteremo rapidamente i comandi SQL di base per iniziare fin da subito a prendere dimestichezza con il DBMS.
Preparazione degli esempi
Come nel mondo relazionale, anche in OrientDB SQL supporta le quattro operazioni CRUD: creazione, lettura ("read", in inglese), aggiornamento ("update") e cancellazione di dati ("delete").
Per iniziare, abbiamo bisogno di:
- un'istanza in esecuzione di OrientDB: avvieremo lo script server.sh (server.bat in Windows) contenuto nella cartella bin;
- un client per eseguire le query. In questa lezione, utilizzeremo la console testuale avviabile con lo script bin/console.sh, ma si potranno svolgere le stesse operazioni tramite Studio, l'interfaccia web presentata nelle lezioni precedenti.
- un database: ne creeremo uno nuovo in remoto:
CREATE DATABASE remote:localhost/testsql root topolino plocal - una classe che useremo in modalità schema-less, creata con il comando che segue:
CREATE CLASS PersonaL'output che otterremo ci avviserà di quante sono le classi attualmente definite nel database:
Class created successfully. Total classes in database now: 11
Alla classe viene associato anche un cluster di default, al quale è stato assegnato un numero identificativo pari a 11.
Panoramica di comandi SQL
Per prima cosa, inseriamo nel database alcuni dati:
INSERT INTO Persona(nome,cognome) VALUES ('paolo','rossi')L'inserimento produrrà un nuovo record composto da due campi, contraddistinto da id #11:0, ossia numero di cluster concatenato al numero di record. Inseriamo quindi altri record:
INSERT INTO Persona(nome,cognome,eta) VALUES ('silvio','bianchi',51)
INSERT INTO Persona(nome,cognome,citta) VALUES ('elena','verdi','Milano')
Anche in questi casi, ogni INSERT ha prodotto un nuovo record, ognuno con il suo id. Visualizziamoli mediante query:
SELECT * FROM PersonaL'output è il seguente:
----+-----+-------+------+-------+----+------
# |@RID |@CLASS |nome |cognome|eta |citta
----+-----+-------+------+-------+----+------
0 |#11:0|Persona|paolo |rossi |null|null
1 |#11:1|Persona|silvio|bianchi|51 |null
2 |#11:2|Persona|elena |verdi |null|Milano
----+-----+-------+------+-------+----+------Riassumiamo gli aspetti più interessanti emersi sinora:
- non abbiamo progettato alcuna strutturazione dei dati, come sarebbe avvenuto nei database relazionali. Piuttosto abbiamo definito un'entità logica, una classe, senza neanche definirne le proprietà. La sua definizione ha automaticamente prodotto un nuovo cluster;
- i record inseriti hanno tutti strutture interne diverse;
- ogni record ha un numero progressivo che, congiuntamente all'identificativo del cluster, contribuisce a formare il RID, vero elemento di riconoscimento univoco del record.
Per la selezione, possiamo scegliete di utilizzare anche la clausola WHERE:
SELECT * FROM Persona WHERE @rid=#11:1Il risulta mostra il record selezionato in base al suo RID:
----+-----+-------+------+-------+----
# |@RID |@CLASS |nome |cognome|eta
----+-----+-------+------+-------+----
0 |#11:1|Persona|silvio|bianchi|51
----+-----+-------+------+-------+----La seguente query recupererà invece i record in cui è presente un campo cognome valorizzato con la stringa rossi:
SELECT * FROM Persona WHERE cognome='rossi'Il risultato è il seguente:
----+-----+-------+-------+-----
# |@RID |@CLASS |cognome|nome
----+-----+-------+-------+-----
0 |#11:0|Persona|rossi |paolo
----+-----+-------+-------+-----
Per apportare ulteriori modifiche al set di dati che stiamo creando, potremo utilizzare le operazioni di DELETE e UPDATE. Se volessimo cambiare il campo citta nel record in cui esso vale Milano, potremmo ricorrere al seguente comando:
UPDATE Persona SET citta='Torino' WHERE citta='Milano'Come risposta ci verrà comunicato se l'operazione è andata a buon fine e quante righe sono state modificate.
La cancellazione dei record in cui il campo cognome ha valore bianchi viene richiesta nel seguente modo:
DELETE FROM Persona WHERE cognome='bianchi'SQL "visuale"
Come detto in precedenza, le stesse operazioni che abbiamo svolto da riga di comando possono essere eseguite da Studio, l'interfaccia web. Nello specifico, i comandi SQL potranno essere inseriti nella prima scheda, intitolata Browse, mentre per visualizzare le classi a nostra disposizione potremo sfruttare lo Schema Manager, presente nella scheda Schema.
A titolo esemplificativo, vediamo come apparirà la riga relativa alla classe Persona nello Schema Manager:

Come vediamo, troviamo riportati tutti i dati incontrati sinora. Alla classe corrisponde un solo cluster con id 11. Vi sono contenuti due record e sulla destra sono presenti dei pulsanti per attivare le principali operazioni: una query che mostrerà tutti i record associati, la creazione di un nuovo record o la cancellazione della classe intera.
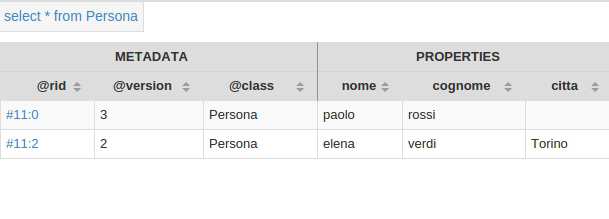
L'immagine seguente mostra il risultato ottenuto cliccando su Query All. In alto a sinistra appare la query invocata, un SELECT che richiama tutti i record presenti, e nella parte centrale vediamo le informazioni reperite. Ogni record è contraddistinto dal campo @rid e presenta una serie di proprietà, quando valorizzate.
Se vuoi aggiornamenti su Database inserisci la tua email nel box qui sotto:
