
Nelle lezioni precedenti abbiamo appreso come predisporre un server OrientDB funzionante. Abbiamo inoltre iniziato ad usare la console da riga di comando tramite la quale ci siamo connessi al servizio e creato un primo database. La console permette di svolgere qualunque operazione ma in molti casi può essere utile avere a disposizione un'interfaccia visuale. OrientDB ne possiede già una, accessibile via browser subito dopo l'avvio del server, che prende il nome di Studio.
Studio: accesso all'interfaccia
Assumiamo di avere a disposizione un'installazione in esecuzione di OrientDB. Ricordiamo che l'avvio del server deve essere svolto tramite script server.sh (server.bat per utenti Windows) collocato all'interno della cartella bin.
L'interfaccia di Studio sarà disponibile all'indirizzo http://localhost:2480/.
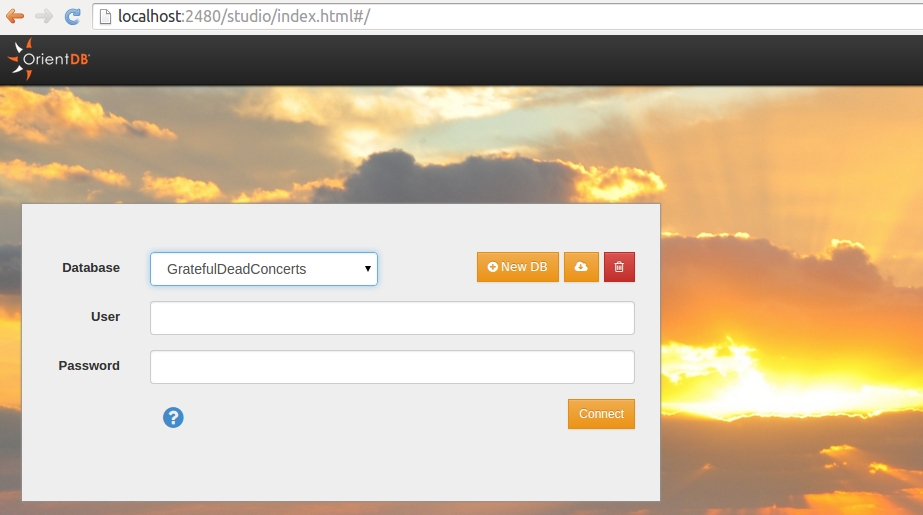
Una volta aperta la pagina con un browser web, vedremo un form per il login che permette di connetterci al database, così come abbiamo fatto da riga di comando. Dovremo indicare il nome di un database, nonchè username e password di un account abilitato all'accesso, configurati nel file config/orientdb-server-config.xml, come spiegato nelle lezioni precedenti.
Potremo quindi svolgere altre tre operazioni fondamentali: creazione di un nuovo database, importazione di un database e cancellazione di uno esistente. Quello che ci interessa fare ora è consultare il database di prova, dii nome GratefulDeadConcerts.
Gestione del database
Una volta effettuato l'accesso, ci si trova in una schermata strutturata a schede che mostra i principali settori di interesse che possono essere gestiti in un database:
-
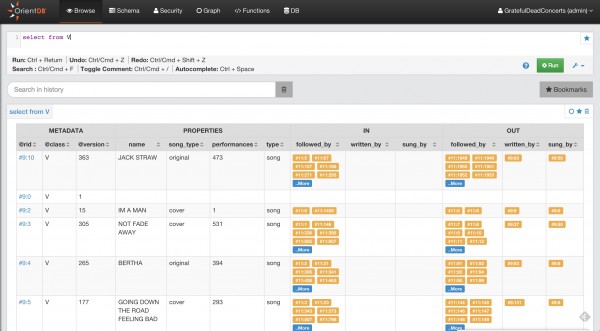
Browse: è il luogo in cui possono essere eseguite delle query. Vedremo che OrientDB permette di svolgere interrogazioni e comandi sui propri dati in linguaggio SQL - una versione simile, nella forma, a quella del mondo relazionale ma specifica di questo DBMS - e Gremlin, un linguaggio fondato su Groovy, studiato appositamente per i database a grafo. Sulla destra si notano tre comandi. Quello con etichetta Run eseguirà la query inserita, Explain analizzerà la query, offrendo spunti utili a correggerne le inefficienze, mentre Bookmarks mostrerà le query contrassegnate come preferite (funzionalità utile nel caso si vogliano memorizzare interrogazioni ripetute di frequente);
Figura 2. Esecuzione di una query (click per ingrandire)
-
Schema: OrientDB, in quanto database NoSQL, può lavorare in modalità schema-less, ossia senza una struttura prestabilita per i dati. In alcuni casi è tuttavia possibile strutturarli tramite le classi. Per lavorare ad una strutturazione dei dati in maniera visuale si può ricorrere allo Schema Manager, collocato in questa sezione di Studio. Vengono qui mostrate le classi al momento disponibili e c'è la possibilità di modificarle e crearne di nuove;
-
Security: ogni database ha un insieme di utenti che può farvi accesso. Consultando questa sezione relativamente al database GratefulDeadConcerts si vede che anche qui ne sono configurati tre: admin, read, write. In questa pagina, si possono creare nuovi utenti da associare al database;
-
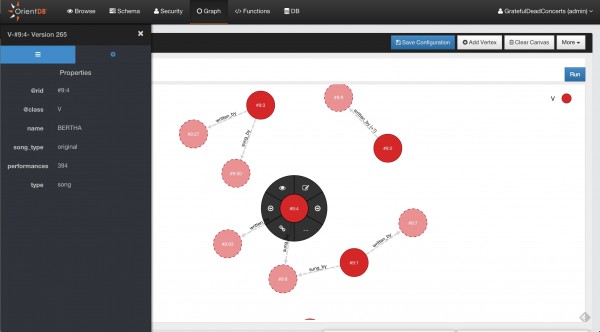
Graph: la strutturazione dei dati a grafo è particolarmente adatta ad alcuni tipi di progetti, ma non sempre la visualizzazione dei dati risulta particolarmente intuitiva. Per questo, Studio è stato dotato di uno strumento per visualizzare i dati in forma di grafo, e dalla versione 2.0 è stata introdotta la possibilità di interagire con i nodi rappresentati. Sarà quindi possibile aggiungere, cancellare e modificare i vertici, nonchè ispezionarli;
Figura 3. Visualizzazione di grafi (click per ingrandire)
-
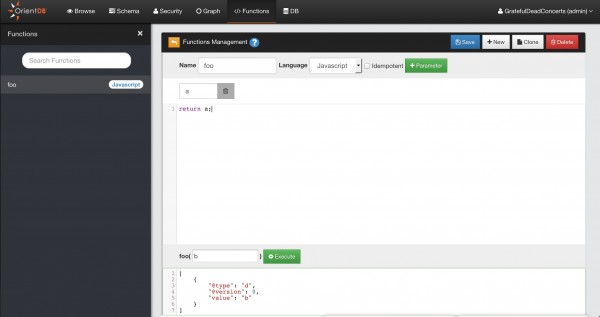
Functions: questa sezione permette di creare funzioni da memorizzare nel database. È necessario assegnare un nome ad una funzione e specificare in quale linguaggio sarà scritta, scegliendo nel menu a tendina tra SQL, JavaScript e Groovy. Nel campo centrale andrà inserito il corpo della funzione e si potranno indicare eventuali parametri. Alla pressione del tasto Execute, se si sarà svolto tutto correttamente, il risultato sarà mostrato nel campo di testo in basso, espresso in formato JSON, e contenuto nel campo
value;Figura 4. Gestione delle funzioni (click per ingrandire)
-
DB: l'ultima schermata mostra caratteristiche generali del database. Essa è a sua volta suddivisa in tre porzioni: Structure, Configuration ed Export. La prima mostra l'elenco dei cluster; vedremo nel seguito della guida che essi corrispondono concettualemente alle tabelle dei database relazionali. Qui vediamo una sorta di elenco di tabelle con indicazione del numero di record associati con ognuna di esse. Configuration, la seconda scheda, mostra un elenco di configurazioni che possono essere assegnate al database, mentre la terza, Export, offre la possibilità di esportare il database in formato JSON.



A questo punto abbiamo due strumenti per poter sperimentare quello che vedremo nel prosieguo della guida: la console testuale e l'interfaccia visuale. Più avanti vedremo un terzo modo che permette operare tramite il DBMS sui nostri dati, tramite quella che è in fin dei conti la modalità principale di utilizzo: le API di programmazione.
Se vuoi aggiornamenti su Database inserisci la tua email nel box qui sotto:
