
Tra i database di informazioni strutturate, quelli relazionali sono probabilmente i più diffusi. Migrare i dati di un’applicazione da una struttura relazionale a MongoDB non è un'operazione banale. Essendo MySQL il database più diffuso su web, in questa lezione vedremo in particolare la migrazione da questo RDBMS, anche se gran parte dei concetti sono validi per qualsiasi altro database SQL.
Ripensare la struttura dei dati
La differenza più importante tra i due modelli, ovviamente, è che mentre MongoDB si basa su documenti che possono essere incorporati o collegati senza vincoli di integrità, il nostro RDBMS utilizza tabelle che possono avere tali vincoli, che assicurano in ogni momento del tempo che le relazioni tra le tabelle siano valide (coerenza).
Un altro fattore importante da considerare è la validazione. Se ci siamo affidati a MySQL per la validazione dei dati (ad esempio impostando la lunghezza massima di un campo codiceFiscale, oppure dichiarando DATE il campo dataDiNascita), bisogna tenere a mente che, su MongoDB, ciò non è possibile. Di conseguenza dovremmo implementare ogni meccanismo di validazione per via applicativa, implementandola via software (problema che, generalmente, è di facile risoluzione se abbiamo accesso al codice dell'applicazione).
Si possono seguire diversi approcci per decidere come migrare lo schema del database. In generale, poiché i modelli di dati sono considerevolmente differenti, è consigliabile pensare di migrare il modello non da tabelle a documenti, ma da entità/relazioni a documenti. Oppure, partendo dalle tabelle, si può cercare di aggregarle logicamente in base al loro tipico utilizzo, per esempio basandoci sul fatto che una modifica in una delle tabelle dell’aggregato risulta nel pensare tutto l’aggregato come modificato, per poi riconoscere questi aggregati come documenti. Ricordiamo che il concetto di aggregato è di particolare importanza se si sviluppa con una logica di Domain Driven Design.
Il rischio, altrimenti, è di rappresentare tabelle in documenti a grana troppo fine, il che può dare, oltre alla difficoltà di interrogazione, anche problemi di performance e difficoltà di manutenzione.
Vediamo subito un esempio:
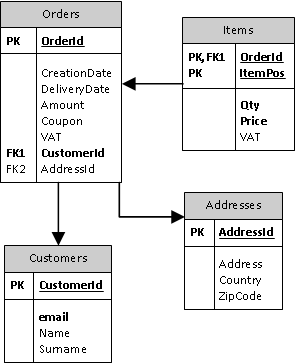
Abbiamo rappresentato un database di ordini per un sito di e-commerce. Gli ordini si riferiscono ad un cliente, hanno un indirizzo di spedizione e si compongono di articoli, ognuno con i suoi dati. Se proviamo ad aggregare le tabelle, vediamo che Order, Address e Item dovrebbero essere considerati parti di un unico documento. Infatti, una modifica ad una voce dell’ordine o all’indirizzo di spedizione risulterebbe in una modifica all’intero ordine. Invece la tabella Customer dovrebbe appartenere ad un altro documento, perché può essere ragionevolmente pensata come entità distinta dai suoi Order. Naturalmente le scelte dipendono molto dal contesto di utilizzo dell’applicazione.
A questo punto possiamo strutturare il nostro nuovo database MongoDB in questo modo:
- innanzitutto creiamo un database che possiamo chiamare sales;
-
poi creiamo due collezioni:
- una collezione customers per contenere i documenti con le informazioni sui clienti;
- una collezione orders, in cui mettiamo invece gli ordini effettuati dai clienti. Ogni documento avrà l’ID di un oggetto della collezione customer per specificare a quale cliente faceva riferimento l’ordine. A parte ciò, il documento in orders dovrebbe avere tutti i dati necessari per lavorare con l’ordine (spedizione, e-mail del cliente). Ciò porta inevitabilmente ad una certa ridondanza, che però è il compromesso per evitare di effettuare due query al fine di ricostruire l’ordine nella sua interezza, come vedremo più avanti.
Fatto ciò, non è necessaria nessun'altra considerazione relativa alla struttura del database, poiché, come detto nelle precedenti lezioni, non c’è bisogno di creare nessuno schema del database.
È ovvio che in caso di relazioni molti a molti, che coinvolgono più entità, è difficile utilizzare l’approccio del documento incorporato che abbiamo appena presentato. In tal caso bisognerà ricorrere a più collezioni, una per entità, ed utilizzare dei collegamenti tramite id tra gli elementi delle collezioni. Ovviamente, ricordiamo di nuovo che MongoDB non garantirà la consistenza di questi collegamenti. Va anche considerato che se tutto o gran parte del database si basa su entità molto collegate fra loro e con relazioni che vogliamo salvaguardare con integrità, probabilmente MongoDB non è lo strumento
giusto. Ma se vogliamo rimanere nell’ambito dei database NoSQL si può valutare l’adozione di un database a grafo, ad esempio Neo4j o OrientDB.
Copia dei dati
Lo strumento mongoimport permette di caricare in MongoDB dati provenienti da varie fonti, come JSON o CSV. L’utilizzo di questo strumento è abbastanza semplice: basta specificare un file di partenza, naturalmente un’istanza MongoDB, il database e la collezione di arrivo. Supponiamo di avere un’esportazione CSV da MySQL, avente come prima riga l’intestazione delle colonne; possiamo invocare mongoimport così:
mongoimport --db sales --collection customers --type csv --headerline --file customers.csvQuesto commando importa il file CSV specificato nella collezione di destinazione. Il risultato del comando precedente sarà un messaggio contenente il numero di elementi importati.
Per usare mongoimport, però, è ovviamente necessario avere un’esportazione CSV da MySQL. Il formato CSV è molto semplice: ogni riga corrisponde ad un record, mentre i campi sono separati da virgole. Le stringhe sono delimitate generalmente da doppi apici (“). Per creare un’esportazione da MySQL in CSV, apriamo il client a riga di comando di MySQL e immettiamo la seguente query:
SELECT CustomerId,email,name,surname
FROM customers
INTO outfile 'customers.csv'
FIELDS TERMINATED BY ',' ENCLOSED BY '"' LINES TERMINATED BY '\n'
La precedente è una normale SELECT seguita da una direttiva che indica destinazione e formato del file. Purtroppo MySQL non mette le intestazioni nel file, quindi dovremo provvedere noi modificando il file CSV e aggiungendo, nella prima riga, i nomi dei campi. Possiamo ovviamente scegliere nomi diversi rispetto ai campi di MySQL. Ad esempio, se vogliamo usare CustomerId come vero _id di MongoDB, possiamo specificare questo nella prima riga del file CSV:
_id,email,name,surnameQuesto tipo di importazione è molto comoda quando i dati da importare sono semplici e quando non è necessaria alcuna validazione.
Per quanto riguarda la collection orders, è sicuramente poco raccomandabile l’utilizzo di mongoimport: è invece preferibile scrivere un’applicazione, ad esempio in Java o in qualunque altro linguaggio supportato da MongoDB. È ovvio che se l’importazione è un’attività da effettuare una-tantum può essere comodo utilizzare un linguaggio che possa essere eseguito da un interprete (come Python o Scala) in modo da poter correggere rapidamente eventuali errori.
Il nostro programma dovrebbe fare questa sequenza di operazioni:
- collegarsi a MySQL;
-
scorrere la tabella Orders e, per ogni riga:
- prendere l’indirizzo di spedizione dalla tabella Addresses;
- prendere l’elenco delle voci dell’ordine dalla tabella Items;
- creare un documento BSON e inserirlo in MongoDB.
Ad esempio, in Scala, usando una libreria per SQL come Slick, si può scrivere:
val exportOrders = for {
( (o, a),c) <- orders join addresses on (_.AddressId === _. AddressId)
join customers on (_._1.CustomerId === _.CustomerId)
} yield (o, a, c)Questo codice effettuerà la query:
SELECT * FROM Orders
JOIN Adrresses ON Orders. AddressId = Adrresses. AddressId
JOIN Customers ON Orders. AddressId = Adrresses. AddressIdPer creare un ordine, bisogna effettuare un ciclo su exportOrders e leggere da MySQL le voci degli ordini:
val completeOrders =
for((o, a, c) <- exportOrders; i <- items filter (_.OrderId ===o.OrderId))
yield (o,a,c, i)Ciò effettuerà, per ogni ordine, la seguente query:
SELECT * FROM Items WHERE OrderId = :orderIdA questo punto dobbiamo mappare gli oggetti in BSON, utilizzando l’API di MongoDB per Scala, che si chiama Casbah:
val mongoObjects = for ( (o,a,c,i) <- completeOrders)
yield MongoDBObject("_id" -> o.OrderId) ++
("address" -> a.Address) ++
("items" -> i.map(_ => MongoDBObject("price" -> _.Price))
In questo esempio, per brevità abbiamo inserito solo alcuni campi. Una volta inseriti nel database questi documenti, utilizzando la funzione insert, avremo aggiunto i seguenti dati nella collezione orders:
{ "_id" : 32, "address" : "Via Verdi", "items" : [ { "price" : 52.2 } ], "customerEmail": "mongodb@html.it", "customerId": 5 }L’oggetto nella collezione è pronto per essere mostrato all’utente dalle nostre applicazioni client, senza ulteriori operazioni di “join” fra collezioni.
Se vuoi aggiornamenti su Database inserisci la tua email nel box qui sotto:
