
Sinora abbiamo conosciuto la ricchezza di funzionalità dei DataFrame Pandas e di quanto il loro legame
sia stretto con i principali ambiente per la data visualization ovvero Matplotlib e
Seaborn. Ogni volta che avremo dati in una struttura Pandas e ci sarà necessario doverli visualizzare (casistiche assolutamente comuni per un data scientist) potremo passarli ad
oggetti Matplotlib e Seaborn ed ottenere visualizzazioni con il massimo del dettaglio nonchè una perfetta personalizzazione. Eppure è importante sapere che Pandas stesso mette a disposizione
tutto il necessario per visualizzare i propri dati. In pratica, ogni DataFrame espone delle funzionalità per realizzare grafici e le porte di tutto questo possono essere dischiuse con il metodo
plot.
Prepariamo i dati
Utilizzeremo per questo esempio un DataFrame generato casualmente e popolato da numeri interi, ciò ci permetterà di essere pronti velocemente al lavoro senza dover caricare alcun dataset esterno.
Ecco il comando necessario:
import numpy as np
import pandas as pd
df = pd.DataFrame(np.random.randint(0,30,size=(30, 4)), columns=list('ABCD'))Abbiamo fatto uso anche delle funzionalità di NumPy per ottenere quattro colonne ognuna di trenta numeri random denominate
rispettivamente "A", "B", "C" e "D". Con il metodo head possiamo avere uno scorcio sulle prime righe:
A B C D
0 29 2 17 11
1 17 10 3 12
2 8 6 4 6
3 2 10 4 5
4 4 28 7 11Ora siamo pronti per creare i nostri primi grafici con Pandas. Ricordiamo solo che essendo generati casualmente tali dati, ogni sperimentazione del codice offrirà risultati differenti.
Grafici lineari
Come di consueto, iniziamo parlando di come rappresentare grafici a linee, casistica assolutamente comune. Con Pandas inizieremo sempre invocando il
metodo plot sul DataFrame. Ad esempio:
df.B.plot()genera:
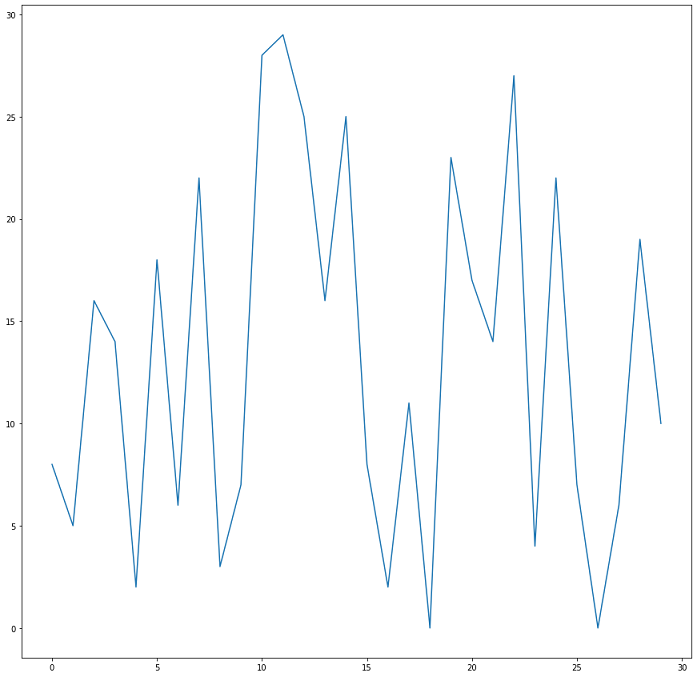
Come si vede, con una rapida catena di riferimenti abbiamo detto che nel DataFrame df cerchiamo la colonna B e di questa vogliamo il grafico lineare (metodo plot). Avremmo
potuto anche richiedere una rappresentazione di più colonne insieme con df[['A','B']].plot(). In pratica, sfruttiamo l'indirizzamento a colonne da sempre disponibile in Pandas
ma non per stampare i dati ma per averne un plotting a video.
Tra gli argomenti che possiamo passare al metodo plot c'è figsize che permette di specificare il ridimensionamento che vogliamo applicare al grafico fornito:
ad esempio, figsize=(15,15).
Il metodo plot è un tool generico in grado di fornire molti grafici diversi che potranno essere selezionati con l'argomento kind.
Altri tipi di grafici
Se volessimo avere uno scatter, grafico a punti molto comune, potremmo utilizzare:
df.plot(x="A", y="B", kind="scatter")Con kind="scatter" indichiamo il tipo di grafico mentre con x e y specifichiamo quale delle colonne farà da ascissa e quale da ordinata. Ecco
il risultato:
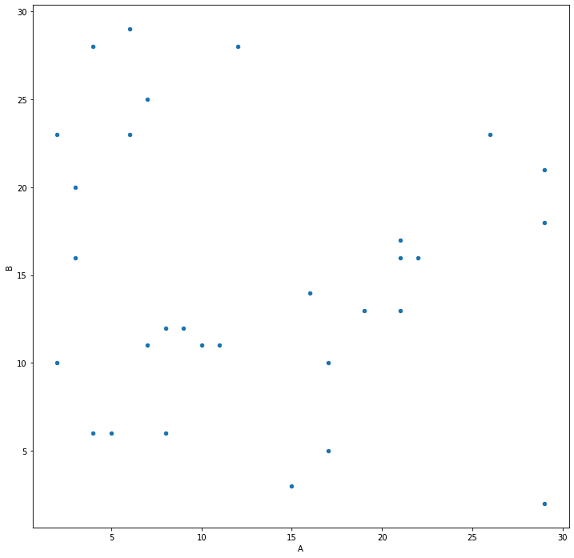
Il parametro kind offre il vantaggio di passare sotto forma di stringa il tipo di grafico che ci interessa avere e ciò, ai fini della configurabilità dei nostri script, è utile per
un "settaggio" al volo del suo valore. Tuttavia, si può specificare direttamente il tipo di grafico che si desidera passando per i metodi offerti dall'oggetto plot
disponibile in ogni DataFrame. Ad esempio, lo scatter precedente si sarebbe potuto ottenere con: df.plot.scatter(x="A", y="B").
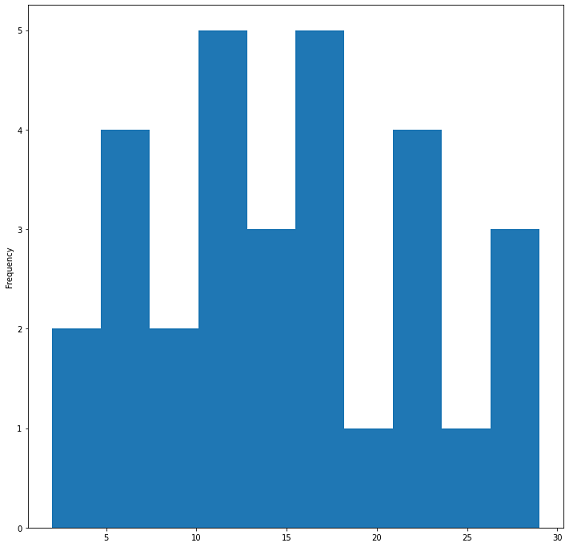
Si potrà avere anche un istogramma per la distribuzione statistica con df.B.plot(kind="hist") anche questo basato sui dati della colonna B. Otteniamo:
Per avere un grafico a barre invece il valore che dovrà essere passato al parametro kind è bar pertanto df[['A','B']].plot(kind="bar")
fornirà:
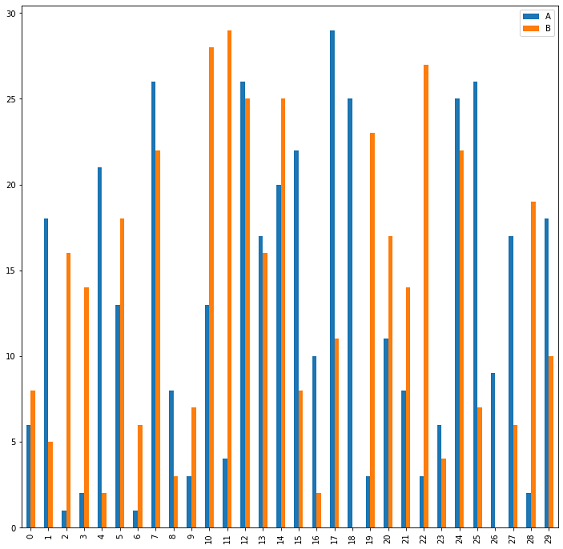
Si noti che nella selezione abbiamo indicato due colonne e Pandas ha tenuto conto di entrambe rappresentando per ogni porzione di ascissa una doppia barra con colori distinti. Le barre
possono anche essere disegnate orizzontalmente utilizzando df[['A','B']].plot(kind="barh") o df[['A','B']].plot.barh(). Ultimo tipo di rappresentazione che
mostriamo è un modo molto rapido per osservare la densità dei valori: df.plot.kde(). Ecco quanto produce:
In conclusione, possiamo dire che la visualizzazione diretta tramite Pandas offre il grande vantaggio di risultare pratica e molto comoda per le esplorazioni dei dati, senza nulla togliere
però alle svariate possibilità che mettono a disposizione Matplotlib e Seaborn.
Se vuoi aggiornamenti su Essentials inserisci la tua email nel box qui sotto:
