
Nella lezione precedente abbiamo gettato le basi per la creazione della nostra GAN. Adesso è arrivato il momento di sviluppare i suoi elementi essenziali, come il Generatore e il Discriminatore. Cominciamo con quest'ultimo.
Il Discriminatore
Come anticipato nelle precedenti lezioni, il Discriminatore è una rete neurale. Lo implementeremo come una classe che eredita da nn.Module. Ci occuperemo per prima cosa di inizializzare la rete ed implementare la funzione forward().
Diamo un'occhiata al costruttore della classe del Discriminatore, chiamata propriamente Discriminator:
class Discriminator(nn.Module):
def __init__(self):
# initialise parent pytorch class
super().__init__()
# define neural network layers
self.model = nn.Sequential(
nn.Linear(4, 3),
nn.Sigmoid(),
nn.Linear(3, 1),
nn.Sigmoid()
)
self.loss_function = nn.MSELoss()
self.optimiser = torch.optim.SGD(self.parameters(), lr=0.01)
self.counter = 0
self.progress = []
def forward(self, inputs):
return self.model(inputs)
def train(self, inputs, targets):
outputs = self.forward(inputs)
# loss
loss = self.loss_function(outputs, targets)
self.counter += 1
if (self.counter % 10 == 0):
self.progress.append(loss.item())
pass
if (self.counter % 10000 == 0):
print("counter = ", self.counter)
pass
self.optimiser.zero_grad()
loss.backward()
self.optimiser.step()
pass
Quello che possiamo immediatamente apprezzare in questo codice è che
abbiamo definito:
-
una serie di livelli per mezzo di
nn.Sequential, attraverso
i quali scorrerà l'informazione; -
una funzione di perdita basata sull'errore quadratico medio (Mean
Square Error, MSE); -
la discesa stocastica del gradiente per l'aggiornamento dei parametri
apprendibili della rete.
Successivamente utilizziamo un contatore counter,
inizialmente impostato su 0, e una lista vuota chiamata progress per tenere traccia dei progressi della loss durante
l'addestramento.
Per passare le informazioni attraverso la rete, PyTorch necessita di un
metodo forward(). Dobbiamo quindi crearne uno, non necessariamente complesso.
Il metodo forward() deve essere affiancato da un metodo train(), che riceve sia gli input
che gli output della rete. In questo modo esso sarà successivamente in grado di
confrontarli con l'output che la rete dovrebbe effettivamente restituire,
calcolando la loss.
La funzione train() contiene, in pratica,
lo standard di quello che usualmente è presente in una funzione di
addestramento. Per prima cosa, vengono usati gli input per ottenere l'output dalla rete neurale, in modo da poter poi calcolare la loss confrontandola con i target, ovvero con gli
output che la rete dovrebbe effettivamente restituire. I gradienti
all'interno della rete vengono calcolati da questa loss e i parametri che
la rete apprende vengono di volta in volta aggiornati dall'ottimizzatore.
Grazie al contatore counter, nella funzione train() teniamo anche traccia di quante volte questa viene
chiamata e aggiungiamo, ogni 10 chiamate, la loss alla lista progress.
Potremmo anche pensare di aggiungere una funzione plot_progress() alla nostra classe per disegnare un grafico
delle loss accumulate durante l'addestramento.
def plot_progress(self):
df = pandas.DataFrame(self.progress, columns=['loss'])
df.plot(ylim=(0, 1.0), figsize=(16,8), alpha=0.1, marker='.',
grid=True, yticks=(0, 0.25, 0.5))
pass
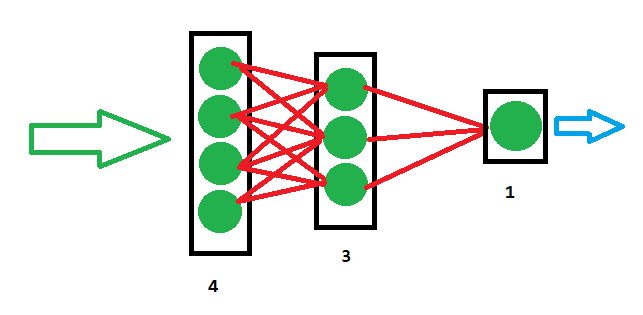
La semplice rete appena definita questa richiede 4
valori di input,
come possiamo vedere analizzando la definizione
nn.Linear(4, 3). Il risultato della rete neurale sarà invece un singolo valore, come si evince da
nn.Linear(3, 1). I layer intermedi nascosti sono tre, come costituendo quindi una rete con una struttura simile alla seguente:
Testare il Discriminatore
Per testare il Discriminatore, possiamo innanzitutto vedere se sia o meno in grado di riconoscere i dati reali dal rumore casuale. Creiamo quindi una funzione che si occupa di generare rumore:
def generate_random(size):
random_data = torch.rand(size)
return random_data
Questa funzione ritorna un tensore pari alla dimensione passata come argomento. Ad esempio, generate_random(4) ritorna un tensore di dimensione pari a
4 con valori casuali tra 0 e 1.
Ora addestriamo il Discriminatore per mezzo di un ciclo e lo premiamo se
classifica:
-
Il pattern
1010come vero, ovvero con un output pari a1.0 -
Il rumore casuale come falso, ovvero con un output pari a
0.0
D = Discriminator()
for i in range(10000):
# real data
D.train(generate_real(), torch.FloatTensor([1.0]))
# fake data
D.train(generate_random(), torch.FloatTensor([0.0]))
pass
Il training viene eseguito 10.000 volte. Alla funzione train() del Discriminatore vengono passati i dati reali dalla
funzione generate_real(), implementata alla fine della lezione
precedente, e un tensore target con il valore 1.0, per
indicare il valore logico vero. Questo servirà a incoraggiare la rete a
restituire 1.0 quando vedrà dati reali con il pattern 1010. Allo stesso modo, la funzione train() del
Discriminatore riceverà un rumore casuale dalla funzione generate_random(), implementata poco prima in questa lezione,
e un tensore target con valore di 0.0, per incoraggiarlo a
restituire un valore pari a 0.0 quando vedrà dati che non sono
uguali al pattern 1010.
Una volta eseguito questo ciclo di addestramento possiamo disegnare il
grafico della loss per vedere come è andato l'addestramento:
D.plot_progress()
Possiamo constatare che la perdita si aggira inizialmente
intorno a 0.25, scendendo poi verso lo zero man mano che il
Discriminatore migliora nel riconoscere il pattern 1010 dal
rumore.
A questo punto, visto che abbiamo addestrato il nostro Discriminatore, se
gli passiamo un pattern 1010 dovremmo aspettarci un output
vicino a 1.0. Se invece gli passiamo uno numero casuale
dovremmo aspettarci un output vicino a 0.0.
print(D.forward(generate_real()).item())
print(D.forward(generate_random(4)).item())Con questo esempio siamo in grado di verificare il corretto funzionamento del nostro Discriminatore. Nella prossima lezione ci occuperemo dello sviluppo del Generatore.
Se vuoi aggiornamenti su Essentials inserisci la tua email nel box qui sotto:
