
Come abbiamo visto nella precedente lezione, in una GAN sia il generatore che il discriminatore necessitano di essere addestrati. La cosa di preminente importanza è che entrambi vengano addestrati insieme, senza che l'addestramento di uno si allontani troppo dall'altro.
In questa lezione capiremo come funziona l'addestramento del generatore e del discriminatore di una GAN, passando subito alla pratica e costruendo (in Python) una rete GAN capace di generare un particolare pattern numerico.
GAN: Training
Ci serviremo di un algoritmo a 3-step, che rappresenta il cuore delle GAN e che consiste nei seguenti passaggi:
- Mostrare al discriminatore i dati reali, etichettati con un valore di verosimiglianza pari a 1
- Mostrare al discriminatore l'uscita del generatore, etichettata con un valore pari a 0.0
- Mostrare al discriminatore l'uscita del generatore, facendo sì che il generatore produca un risultato pari a 1.0
Per comprendere al meglio questi passaggi, analizziamoli da vicino.
Step 1
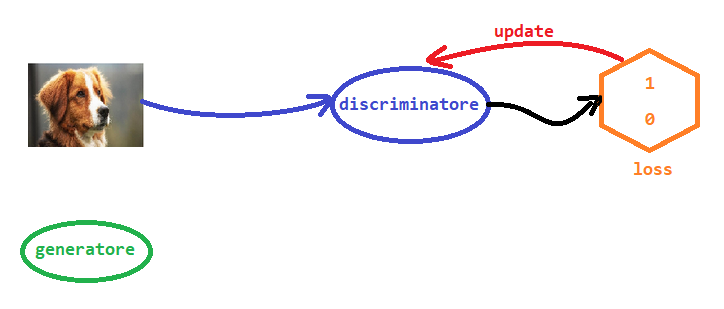
Questo passaggio è quello più semplice. Mostriamo al discriminatore un'immagine reale da un set di dati, e gli chiediamo di classificarla. L'output dovrebbe essere 1.0, e usiamo l'errore per aggiornare il discriminatore.
Step 2
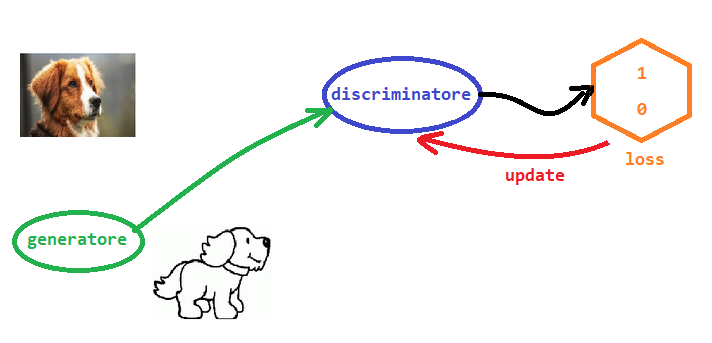
Nel secondo passaggio dell'algoritmo, mostriamo al discriminatore un'immagine creata dal generatore, quindi non reale, che deve necessariamente essere classificata dal discriminatore con un valore pari a 0.0. Usiamo l'errore per aggiornare solo il discriminatore. A questo proposito, è bene chiarire che dobbiamo stare attenti a non aggiornare il generatore in questo passaggio, poiché non vogliamo premiarlo per essere stato "scoperto" dal discriminatore.
Step 3
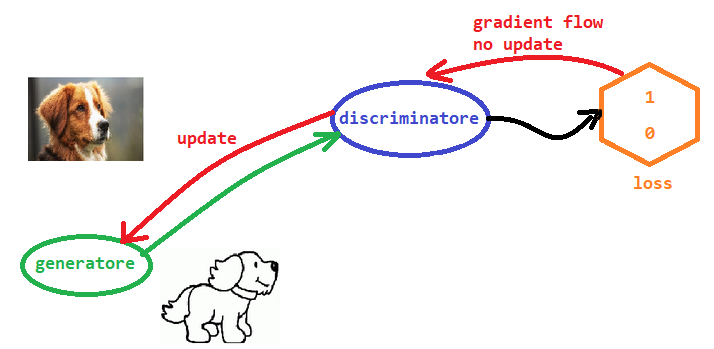
L'ultimo passaggio si occupa di addestrare il generatore. Lo usiamo per generare un'immagine che viene presentata al discriminatore per classificarla. L'output del discriminatore dovrebbe essere 1.0. Vogliamo, cioè, che il generatore inganni il discriminatore nel classificare l'immagine come reale (pur essendo questa falsa). L'errore viene utilizzato solo per aggiornare il generatore. Non aggiorniamo il discriminatore perché non vogliamo incoraggiarlo a sbagliare le sue classificazioni.
Come abbiamo visto, il processo di addestramento del discriminatore e del generatore non è poi così complesso. Vediamo quindi come mettere in pratica questi concetti.
La nostra prima GAN
L'obiettivo che ci prefiggiamo è quello di costruire una GAN in cui il generatore impari a creare un pattern di valori 1010: un compito chiaramente molto più semplice della generazione di immagini, ma che risulta utile dal punto di vista didattico.
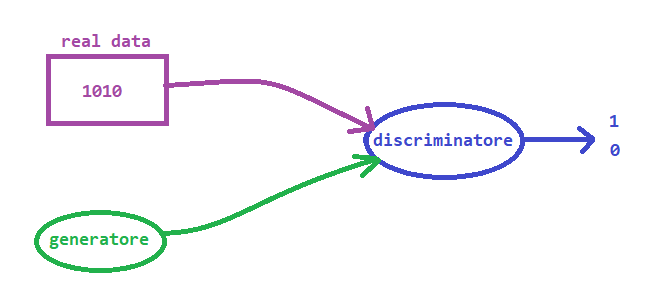
Come possiamo vedere dalla figura, il set di dati reali è stato sostituito con una funzione che ci dà sempre un pattern di valori 1010. Questo implica che non avremo bisogno di usare l'oggetto torch.utils.data.Dataset di PyTorch per una fonte di dati così semplice. Il generatore, invece, è una rete neurale che ha il compito di generare 4 valori, che dopo l'addestramento dovrebbero dare vita al pattern di valori 1010. Il discriminatore allora prende un pattern di 4 valori e cerca di determinare se proviene da fonte di dati reale o dal generatore.
Il Generatore
Cominciamo a scrivere il codice per dare vita alla nostra GAN. Creiamo un nuovo Notebook Jupyter e importiamo le librerie di rito:
import torch
import torch.nn as nn
import pandas
import matplotlib.pyplot as pltCome abbiamo detto la sorgente dei dati reali sarà sempre uguale al pattern di valori 1010, che quindi possiamo codificare per mezzo di una funzione che ritornerà sempre il pattern 1010.
def generate_real():
real_data = torch.FloatTensor([1, 0, 1, 0])
return real_dataPer rendere questa funzione un po' più realistica, possiamo aggiungere un po' di rumore durante la generazione dei valori che andranno a comporre il nostro pattern.
Importiamo quindi la libreria random di Python per utilizzare la sua funzione random.uniform() e modifichiamo la nostra funzione in questo modo:
def generate_real():
real_data = torch.FloatTensor(
[random.uniform(0.8, 1.0),
random.uniform(0.0, 0.2),
random.uniform(0.8, 1.0),
random.uniform(0.0, 0.2)])
return real_dataPraticamente, quello che adesso fa questa funzione è restituire un tensore di 4 valori in cui il primo e il terzo valore sono numeri casuali compresi tra 0,8 e 1,0 e il secondo e il quarto sono numeri casuali tra 0,0 e 0,2.
Se testiamo la funzione, vedremo che il risultato restituito sarà qualcosa simile a questo:
tensor([0.9134, 0.1687, 0.9106, 0.1603])Nella prossima lezione ci occuperemo dello sviluppo del discriminatore, per poi addestrarlo insieme al generatore.
Se vuoi aggiornamenti su Essentials inserisci la tua email nel box qui sotto:
