
Uno dei più grandi contributi che i sistemi informatici offrono al genere umano è la memorizzazione di dati in maniera persistente. Quotidianamente, immense quantità di informazioni vengono affidate a tecnologie che ne garantiscono la conservazione duratura ed un recupero efficiente che ne permetta l'analisi. Da anni, questo ruolo viene interpretato molto bene da un prodotto software completo, efficiente ed affidabile: MySQL. Nel seguito chiariremo sin da subito che cos'è esattamente, a cosa serve e come utilizzarlo, illustrandone anche le principali caratteristiche e potenzialità.
Database e DBMS
I concetti centrali in tema di memorizzazione di dati sono due: database e DMBS.
Il primo indica un sistema di file finalizzato a memorizzare informazioni a supporto di un qualsivoglia software. La struttura interna di un database deve rispettare una certa architettura di immagazzinamento dei dati per poterne permettere il corretto salvataggio, il rispetto dei tipi impiegati e soprattutto agevolarne il recupero, un'operazione generalmente molto onerosa.
Un DBMS è un servizio software, realizzato in genere come server in esecuzione continua, che gestisce uno o più database. I programmi che dovranno interagire quindi con una base di dati non potranno farlo direttamente, ma dovranno dialogare con il DBMS. Esso sarà l'unico ad accedere fisicamente alle informazioni.
Quanto detto implica che il DBMS è il componente che si occupa di tutte le politiche di accesso, gestione, sicurezza ed ottimizzazione dei database.
Database relazionali e RDBMS
I DBMS esistenti non sono tutti della stessa tipologia. Al giorno d'oggi, ad esempio, si parla molto di DBMS NoSQL, nati per venire incontro alle esigenze dei più recenti servizi Web. Eppure un filone molto nutrito di DBMS, cui si deve il funzionamento della maggior parte dei prodotti informatici esistenti oggi, è quello dei cosiddetti RDBMS (Relational DBMS), ispirati dalla Teoria Relazionale. Questa nacque nel 1970 ad opera del britannico Edgar f. Codd. Nonostante i 40 anni abbondanti trascorsi, i suoi principi si dimostrano tuttora attuali.
Un database relazionale è costituito da tabelle, ognuna delle quali è composta da righe identificate da un codice univoco denominato chiave. Le tabelle che compongono il database non sono del tutto indipendenti tra loro ma relazionate da legami logici.
La figura seguente mostra un esempio di database finalizzato a custodire i dati di una biblioteca.
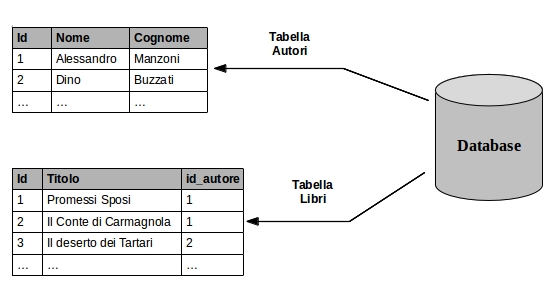
Il database ha due tabelle: Autori e Libri. Ognuna di esse ha una colonna di nome id contenente l'identificativo univoco, la chiave primaria, che permette di riconoscere una riga senza possibilità di confusione. I valori nel campo id_autore della tabella Libri permettono di associare un autore alle sue opere. Ad esempio, “I Promessi Sposi” e “Il Conte di Carmagnola” hanno nel campo id_autore il valore 1, cioè la chiave primaria che nell'altra tabella permette di riconoscere il loro autore, Alessandro Manzoni.
Questo legame creato tramite chiavi prende il nome di relazione.
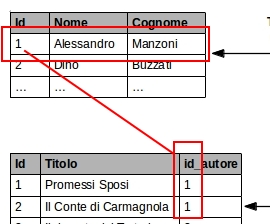
Esistono vari tipi di relazioni. Quello appena descritto è un esempio di relazione uno-a-molti, in quanto ad un autore possono corrispondere più libri. Nel nostro esempio si è assunto che un libro possa avere un solo autore, ma sfruttando relazioni di tipo differente si potranno rappresentare situazioni più vicine alla realtà.
Nel seguito della guida, si approfondiranno tali argomenti fino a vedere una progettazione completa di un database.
Protagonista importante di questa guida, e strumento fondamentale nell'interazione con i DBMS relazionali, è il
(Structured Query Language). Si tratta di un formalismo che permette di indicare al DBMS quali operazioni svolgere sui database che gestisce. Tramite SQL si può attivare qualsiasi tipo di operazione, sia sui dati che sulla struttura interna del database, sebbene le principali (e più frequenti) operazioni ricadono in una delle seguenti quattro tipologie: inserimento, lettura, modifica e cancellazione di dati, tipicamente indicate con l'acronimo CRUD (Create-Read-Update-Delete). Il seguito della guida mostrerà un'ampia panoramica dei comandi SQL, nonché diversi esempi di utilizzo.
MySQL
MySQL è un RDBMS open source e libero, e rappresenta una delle tecnologie più note e diffuse nel mondo dell'IT. MySQL nacque nel 1996 per opera dell'azienda svedese Tcx, basato su un DBMS relazionale preesistente, chiamato mSQL. Il progetto venne distribuito in modalità open source per favorirne la crescita.
Dal 1996 ad oggi, MySQL si è affermato molto velocemente prestando le sue capacità a moltissimi software e siti Internet. I motivi di tale successo risiedono nella sua capacità di mantenere fede agli impegni presi sin dall'inizio:
- alta efficienza nonostante le moli di dati affidate;
- integrazione di tutte le funzionalità che offrono i migliori DBMS: indici, trigger e stored procedure ne sono un esempio, e saranno approfonditi nel corso della guida;
- altissima capacità di integrazione con i principali linguaggi di programmazione, ambienti di sviluppo e suite di programmi da ufficio.
