
Non più solo div
Ecco come si potrebbe codificare l’esempio della lezione precedente utilizzando i nuovi elementi messi a disposizione dall’HTML5:
<!doctype html>
<html lang="it">
<head>
</head>
<body>
<header>
--- Titolo e Testata ---
</header>
<nav>
--- Voci di Menu ---
</nav>
<article>
--- Un Post ---
</article>
<article>
--- Un altro Post ---
</article>
</body>
</html>Come si può notare, i tag introdotti hanno un nome in strettissima attinenza con il proprio contenuto; questo approccio risolve in modo elegante sia il problema dell’utilizzo dell’attributo class con valore semantico, sia la riconoscibilità delle singole aree del documento da parte di un browser. Ma non è tutto; l’introduzione di article, nav, header e altri tag che vedremo, impone anche sostanziose novità al modo in cui lo user-agent deve comportarsi nell’interpretare questi elementi.
Contenuti in una bolla di sapone
Partiamo dal seguente esempio HTML4:
<html>
<body>
<h1>I diari di viaggio:</h1>
<h2>A spasso per il mondo alla scoperta di nuove culture:</h2>
<h3>Giro turistico della Bretagna</h3>
<p>lorem ipsum..</p>
<h3>Alla scoperta del Kenya</h3>
<p>lorem ipsum..</p>
<h3>Cracovia e la Polonia misteriosa</h3>
<p>lorem ipsum..</p>
<p>tutti i viaggi sono completi di informazioni su alberghi e prezzi</p>
</body>
</html>Se lo visualizziamo avremo un risultato assolutamente strutturato come questo:
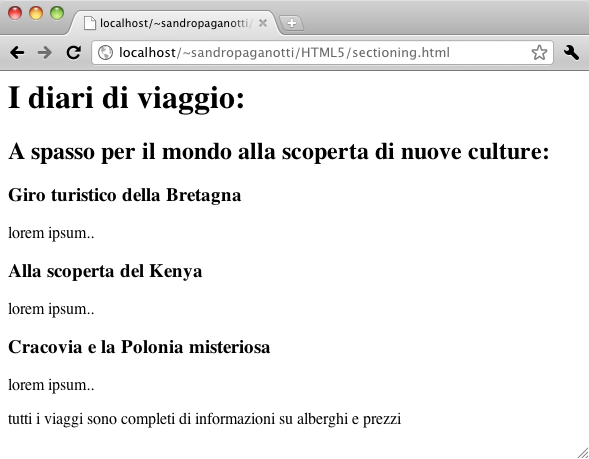
Supponiamo ora di voler dividere i viaggi per continente. Con il modello attuale saremmo obbligati a cambiare l’elemento h3 in h4 in modo da fare spazio alla nuova suddivisione:
<html>
<body>
<h1>I diari di viaggio:</h1>
<h2>A spasso per il mondo alla scoperta di nuove culture:</h2>
<h3>Europa</h3>
<h4>Giro turistico della Bretagna</h4>
<p>lorem ipsum..</p>
<h4>Cracovia e la Polonia misteriosa</h4>
<p>lorem ipsum..</p>
<h3>Africa</h3>
<h4>Alla scoperta del Kenya</h4>
<p>lorem ipsum..</p>
<p>tutti i viaggi sono completi di informazioni su alberghi e prezzi</p>
</body>
</html>Questo accade perché la gerarchia delle intestazioni è assoluta rispetto all’intero documento e ogni tag <h*> è tenuto a rispettarla. Nella maggior parte dei casi però questo comportamento è fastidioso in quanto è molto comune avere a che fare con contenuti che, come articoli o commenti, vorremmo avessero una struttura indipendente dalla loro posizione nella pagina. In HTML5 questo è stato reso possibile definendo una nuova tipologia di content model, chiamato ‘sectioning content’, al quale appartengono elementi come article e section. All’interno di tag come quelli appena citati la vita scorre come in una bolla di sapone, quindi l’utilizzo di un <h1> è considerato relativo alla sezione in cui si trova.
Riprendiamo l’esempio precedente ed interpretiamolo in salsa HTML5:
<!doctype html>
<html>
<head>
<title>I diari di viaggio</title>
</head>
<body>
<header>
<hgroup>
<h1>I diari di viaggio:</h1>
<h2>A spasso per il mondo alla scoperta di nuove culture:</h2>
</hgroup>
</header>
<section>
<h1>Europa</h1>
<article>
<h1>Giro turistico della Bretagna</h1>
<p>lorem ipsum..</p>
</article>
<article>
<h1>Cracovia e la Polonia misteriosa</h1>
<p>lorem ipsum..</p>
</article>
</section>
<section>
<h1>Africa</h1>
<article>
<h1>Alla scoperta del Kenya</h1>
<p>lorem ipsum..</p>
</article>
</section>
<p>tutti i viaggi sono completi di informazioni su alberghi e prezzi</p>
</body>
</html>Molto meglio! Ora i singoli componenti di questo documento sono atomici e possono essere spostati all’interno della pagina senza dover cambiare la loro struttura interna. Inoltre, grazie a queste divisioni, il browser riesce a discernere perfettamente il fatto che l’ultimo paragrafo non appartenga al testo del viaggio in Kenia.
Diamo prova dell’atomicità creando un blocco dedicato all’ultimo articolo inserito: ‘Un week-end a Barcellona’:
<!doctype html>
<html>
<head>
<title>I diari di viaggio</title>
</head>
<body>
<header>
<hgroup>
<h1>I diari di viaggio:</h1>
<h2>A spasso per il mondo alla scoperta di nuove culture:</h2>
</hgroup>
</header>
<article>
<h1>Un week-end a Barcellona</h1>
<p>lorem ipsum..</p>
</article>
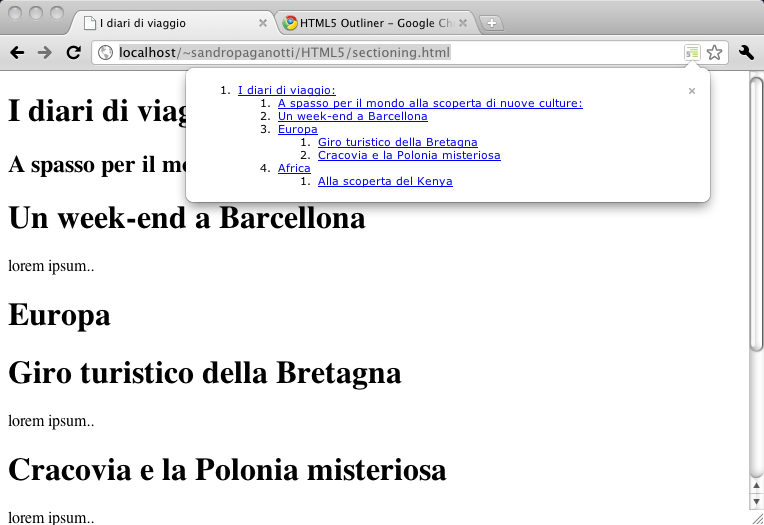
<!-- resto della pagina -->Anche grazie a questo content model l’HTML5 introduce un nuovo e preciso algoritmo per il calcolo dell’outline del documento. La vista ad outline, tipica nei software di word processing e ancora non presente nei browser, è utilissima nella navigazione dei contenuti di una pagina. Sperimentiamo questa feature installando un’apposita estensione per Chromium:

È interessante notare come l’algoritmo non solo identifichi correttamente i vari livelli di profondità, ma per ognuno di essi sappia anche recuperare il titolo adeguato. Nell’HTML5 è vitale che il design della pagina si rispecchi in una outline ordinata e coerente, questa infatti è la miglior cartina tornasole possibile in merito al corretto utilizzo delle specifiche: ad esempio, in una prima revisione della lezione, il codice HTML precedente mancava dell’elemento hgroup, utile a raggruppare elementi che concorrono a formare un titolo. L’errore è stato individuato e corretto proprio grazie alla visualizzazione di una outline errata:
Concludiamo la trattazione di questo content model citando la presenza di alcuni elementi che, pur seguendo le linee interpretative del 'sectioning content', devono essere ignorati dall'algoritmo di outline. Tali tag sono definiti 'sectioning roots' ed il motivo della loro esclusione è legato al fatto che essi non concorrono tanto alla struttura dei contenuti della pagina quanto all'arricchimento della stessa. Fanno parte di questo elenco elementi come: blockquote, details, fieldset, figure e td. Seppur esclusi dall'outline del documento, nulla vieta agli appartenenti di questo gruppo di avere una propria outline interna.
Se vuoi aggiornamenti su Design inserisci la tua email nel box qui sotto:
