

Phidata è una piattaforma open source sviluppata con il compito di facilitare la creazione, il deployment e il monitoraggio di AI Agent o, se preferite, sistemi agentici basati sull'intelligenza artificiale. Offre quindi gli strumenti necessari per sviluppare agenti AI multimodali specifici per un singolo dominio. Dotati di memoria delle sessioni d'uso, conoscenza del contesto di riferimento e capacità di sfruttare strumenti di terze parti.
Sviluppare Agenti AI con Phidata
Con Phidata è possibile implementare un Agente AI a partire da qualsiasi LLM (Large Language Model). La piattaforma supporta l'integrazione di informazioni specifiche da un dominio, permette quindi agli agenti di risolvere problemi complessi con i dati che gli vengono forniti. La memoria integrata consente inoltre di effettuare interazioni a lungo termine, senza perdita di informazioni. Gli agenti possono essere dotati anche di strumenti che permettono l'integrazione e la comunicazione con sistemi esterni in modo da ampliare le funzionalità di base.
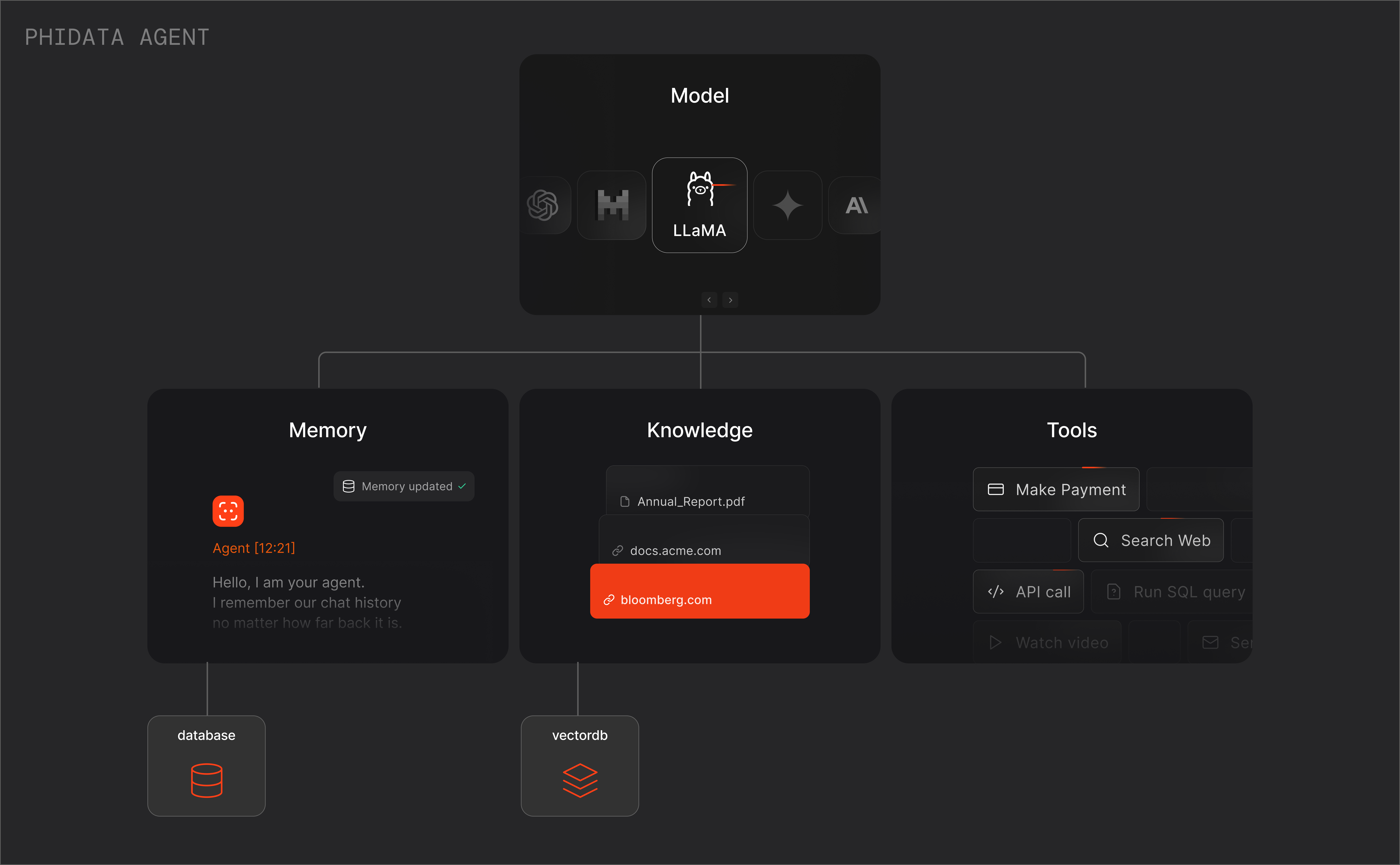
Phidata fornisce modelli full-stack preconfigurati che includono basi di dati, database vettoriali e API. Permette così di passare rapidamente dallo sviluppo alla produzione. La piattaforma supporta il deployment su Cloud personali, gestisce le operazioni DevOps e consente il monitoraggio continuo delle esecuzioni, dei token utilizzati e della qualità degli agenti. Si possono quindi valutare, ottimizzare e migliorare costantemente le prestazioni dei sistemi agentici.
È incluso un debugger built-in con il quale visualizzare i log di debug direttamente da terminale.
Compatibilità con i modelli generativi
La piattaforma è compatibile con diversi provider di modelli linguistici (OpenAI, Anthropic, Ollama, Anyscale..), con la possibilità di convertire qualunque LLM in un agente AI funzionante. Gli utenti possono eseguire l'intero sistema all'interno di un account AWS, inclusi database, interfacce di programmazione e database vettoriali, per ottenere un maggior controllo sui dati.
Per quanto riguarda il supporto ai database, gli sviluppatori del progetto consigliano l'uso di Postgres con PgVector, l'estensione per PostgreSQL che consente di archiviare e interrogare vettori in un database relazionale.
Se vuoi aggiornamenti su AI inserisci la tua email nel box qui sotto:



