

Una delle applicazioni più tipiche del machine learning è quella della classificazione. Gli input di un classificatore possono essere immagini, testi, suoni, video o qualsiasi altro oggetto rappresentabile in qualche modo come sequenza numerica.
Un modello in grado di classificare elementi viene generalmente addestrato su un dataset di elementi (detto training set). Ogni elemento di tale insieme è etichettato con una classe. Se il modello è di buon livello, sarà in grado di generalizzare, e quindi di classificare correttamente in una delle classi già viste nel training set, anche elementi che non ha mai visto.
La capacità di generalizzazione può però essere ulteriormente estesa, facendo sì che un modello sia addirittura in grado di classificare oggetti in classi non viste durante la fase di training. Questa sorta di "estremizzazione" del concetto di classificazione è ciò che cercano di ottenere i ricercatori che si occupano di zero-shot learning.
CLIP, un modello per lo zero-shot learning
CLIP è forse il modello di machine learning attualmente più avanzato, in grado di apprendere in modo efficiente non soltanto le classi osservate in fase di training, ma anche di associare concetti visuali alle relative rappresentazioni testuali. Di fatto, ciò mette insieme le immagini e le loro descrizioni, unendo la classificazione delle immagini con l'analisi del linguaggio naturale.
CLIP è una rete neurale che può essere inserita entro diversi contesti applicativi. Può essere infatti utilizzata sia per effettuare una classificazione (estendendo il dominio ad un numero di classi anche molto maggiore di quello originariamente usato per il modello), sia per semplificare la ricerca di immagini a partire da una descrizione testuale.
CLIP-Italian: la versione italiana di CLIP
Pochi giorni fa, alcuni ricercatori italiani hanno messo a punto una interessante estensione di CLIP, che permette di eseguire sia una classificazione "zero-shot", sia un task di ricerca (image retrieval) a partire da frasi in italiano.
Awesome results from the @huggingface community week! 😍 Very excited about this! ⭐️
We trained an Italian version of @OpenAI's CLIP with 1.4 million images!Works great on image retrieval and zero-shot classification! Demo out soon!
Details: https://t.co/MW8r4kMRTy#NLProc pic.twitter.com/FKG731Tq1Z
— Federico Bianchi (@federicobianchy) July 23, 2021
Il lavoro di definizione di CLIP-Italian, che è già stato reso disponibile su HuggingFace, ha richiesto la raccolta di un dataset di circa 1,4 milioni di immagini, ognuna delle quali associata ad una descrizione in italiano. La preparazione del dataset ha coinvolto in parte una traduzione automatica (al fine di riutilizzare dataset preesistenti, ma in altre lingue), ma sono stati usati anche dati originali.
CLIP-Italian è stato costruito a partire dal modello pre-addestrato Italian BERT (versione destinata alla lingua italiano di BERT, uno dei più noti modelli di NLP), unitamente ad un modello di OpenAI già usato per CLIP, destinato all'apprendimento delle immagini.
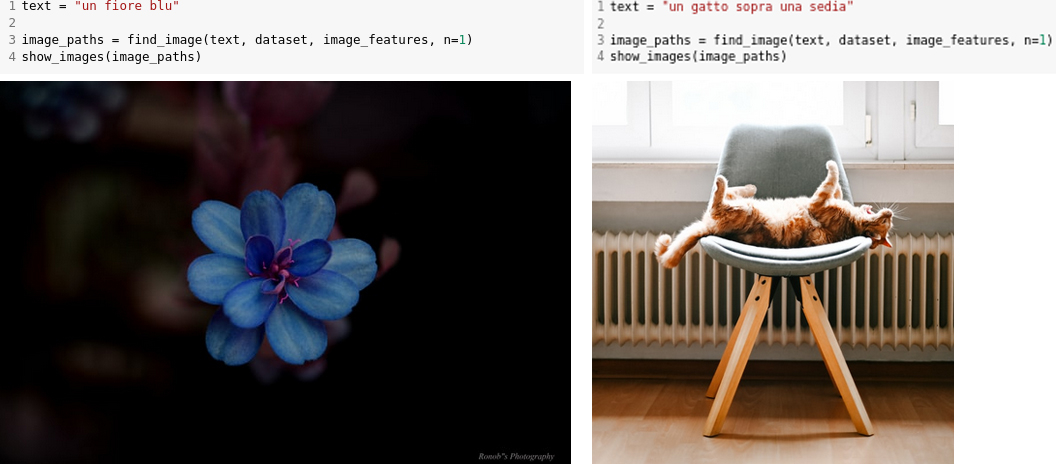
I risultati mostrati sul repository del progetto (pubblicamente accessibile tramite GitHub) permettono di apprezzare la qualità del modello, ad esempio per l'image retrieval:
Se vuoi aggiornamenti su Development inserisci la tua email nel box qui sotto:



