
A partire dal 2010, Microsoft ha investito molto sul progetto Windows Azure, che ora è diventato un ecosistema di prodotti Cloud in grado di competere con i top player del mercato Cloud mondiale. Come avevamo già discusso in uno dei precedenti articoli, per anni il player incontrastato di cloud (principalmente IaaS) è stato Amazon con la sua offerta AWS (Amazon Web Services): Microsoft, a differenza di AWS, si è lanciata nel mercato cloud aggredendo dapprima il panorama PaaS e, solo di recente, il mercato IaaS. Sebbene la decisione potrebbe essere facilmente imputata ad una volontà di non competere con AWS, principale player IaaS, in realtà il modello PaaS è, come spesso ho ricordato in articoli precedenti, l’unico vero modello perseguibile di Cloud Computing che acceleri l’evoluzione IT e che favorisca le best-pratices.
Abbiamo già detto che PaaS significa demandare completamente la governance dei nostri sistemi al fornitore, occupandoci solamente di distribuire le nostre applicazioni e pagare le fatture dei nostri consumi. IaaS d’altronde è un ottimo strumento per abilitare il passaggio al PaaS ma non è, di per sé, sintomo di alcuna evoluzione architetturale, è solamente un modo per spostare i propri server virtuali in un altro datacenter.
Per questo oggi Microsoft, che ha investito principalmente nel PaaS, si ritrova ad essere un player che ha introdotto notevoli innovazioni su questo fronte, come ad esempio i servizi Web Sites, per la distribuzione trasparente di applicazioni web o SQL Database, per la distribuzione trasparente di database SQL Server sul Cloud. Questi due servizi, probabilmente portatori del maggior grado di innovazione complessiva se comparati al resto, sono chiaramente supportati da una serie di altri servizi di alto livello, come i Cloud Services, lo Storage e altri ancora che possono essere facilmente interconnessi tra di loro o, molto spesso, utilizzati stand-alone in scenari di Cloud ibrido.
Abbonamenti
I servizi di Windows Azure sono disponibili a tutti previa registrazione di un account legato ad un Microsoft Account (il precedente Live ID); tale account può essere:
- Trial La trial è attivabile gratuitamente da questo link
- Impegno di consumo
- Pay-per-use Il piano è attivabile da questo link

- MSDN Dev-Test
Una volta acquisito un abbonamento è possibile amministrare i servizi WA direttamente dal pannello di controllo, disponibile all’indirizzo: https://manage.windowsazure.com.
Infrastruttura e portale di gestione
WA è un ecosistema di servizi disponibili su circa una decina di datacenter sparsi per il mondo. Pur essendoci delle forti differenze tecnologiche tra alcuni datacenter (dovuti per esempio alla loro “generazione”, ovvero la tecnologia costruttiva), in WA quasi tutti i servizi sono disponibili su ognuno di essi, garantendo agli utenti un servizio trasparentemente disponibile nella location più vicina al punto di interesse. Al momento i nomi dei datacenter di WA sono:
- North Europe: situato in prossimità di Dublino
- West Europe: situato in prossimità di Amsterdam
- East US: situato in Virginia
- West US: situato in California
- North Central US: situato in prossimità di Chigago, nell’Illinois.
- South Central US: situato in Texas, a San Antonio.
- East Asia: situato vicino a Hong Kong
- Southeast Asia: situato vicino a Singapore
La scelta di uno o l’altro datacenter spetta all’utente, qualunque sia la sua origine o residenza. Questo significa, pur essendo ovvio, che un utente può “accendere” alcuni servizi in Asia e altri in US oppure, nel caso di un business solo italiano, scegliere il datacenter di Amsterdam o di Dublino. Queste scelte si compiono sempre da portale di gestione di WA, che ha questo aspetto:
Il portale di gestione permette di districarsi tra i vari servizi utilizzando le icone sulla sinistra per scegliere l’area di servizi su cui fare zoom; nel caso di più sottoscrizioni, caso raro per chi si avvicina, molto più comune per chi deve gestire servizi di diversi account, è possibile fare un filtro degli abbonamenti tramite il menu in alto a destra, ove è anche possibile recarsi nella sezione dedicata alla fatturazione e al consuntivo dei servizi:
In WA, e più in generale in Microsoft, il servizio è generalmente erogato secondo due modalità:
- La preview
- La GA General Availability
Questa premessa è doverosa perché, elencando i vari pezzi dell’ecosistema, affronteremo servizi rilasciati (in GA) e servizi ancora in preview.
Servizi di IaaS
IaaS sta per Infrastructure as-a Service e, nel gergo comune, significa l’insieme di quei servizi più vicini alla virtualizzazione che alla distribuzione di applicazioni. Non sempre c’è una divisione netta tra IaaS e PaaS, per molti prodotti ma il senso comune attribuisce allo IaaS i seguenti servizi:
- Macchine virtuali
- Servizi di networking
- Servizi di storage
Vedremo però che in WA esiste un servizio di storage (il Blob Storage per esempio) che è dichiaratamente PaaS, poiché al mero storage inteso come Hard Disk o pool di risorse fisiche, aggiunge uno strato di astrazione e programmabilità, mascherando di fatto il suo funzionamento o la sua gestione. Possiamo quindi utilizzare questo esempio per considerare IaaS tutto ciò che il fornitore ci mette in condizione di gestire “a basso livello” e PaaS tutto ciò che il fornitore gestisce per conto suo.
Per fare un esempio: una macchina virtuale, una volta creata, è accessibile tramite RDP (in caso di Windows) o SSH (in caso di Linux): ciò significa che la gestione è completamente sotto il nostro controllo, facendone uno IaaS.
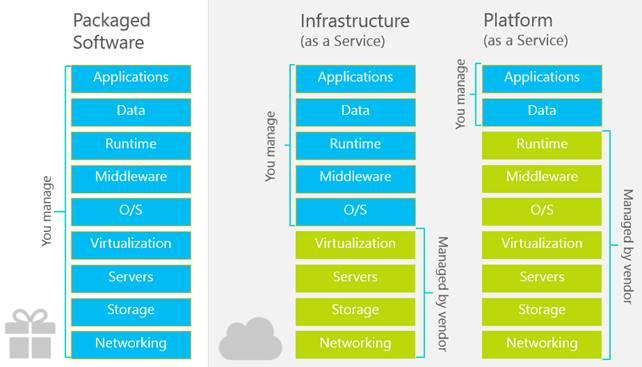
I servizi di Iaas di WA sono chiaramente ben integrati nell’ecosistema di prodotti server di Microsoft. Software come System Center operano molto bene con i sistemi on-premise quanto con le macchine virtuali nel cloud. Alternativamente Microsoft fornisce anche della macchine Linux, accessibili dopo il setup tramite SSH e configurabili a piacimento.
Virtual Machines
Possiamo pensare alle Virtual Machines di WA come ad un pannello di gestione di Hyper-V con funzionalità ridotte. È possibile infatti, tramite il portale, fare provisioning di una o più macchine scegliendone le dimensioni (prefissate tra un range di dimensioni possibili) e il sistema operativo.
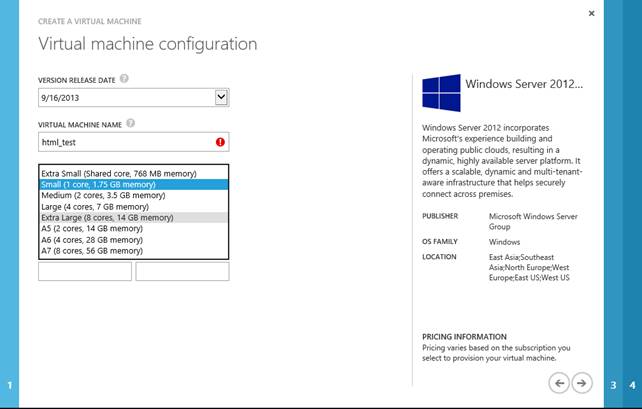
Creare una VM da zero significa, oltre che creare la “prenotazione” delle risorse di calcolo (CPU, RAM, etc) anche creare un HD virtuale sul quale poggeranno i dati persistenti del sistema operativo. Quando scegliamo un sistema operativo tra quelli della galleria:
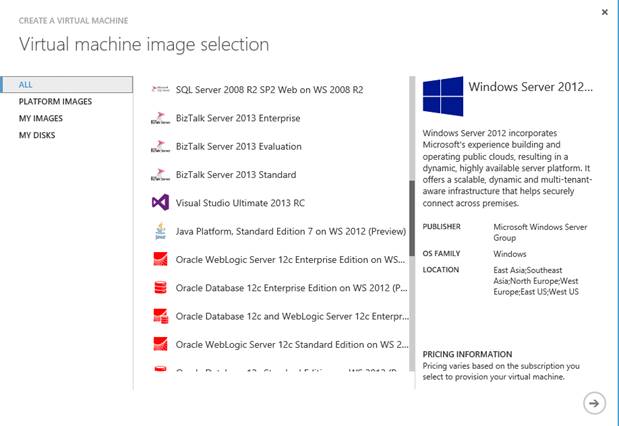
Stiamo implicitamente scegliendo anche la dimensione dell’HD sul quale sarà installato e sul quale sarà possibile, dopo l’avvio, salvare le informazioni persistenti. Si rimarca il concetto di “persistente” perché, in ogni macchina virtuale è sempre disponibile una partizione/disco per i “dati temporanei”, ovvero un disco virtuale per le operazioni di cache sul quale non c’è alcuna garanzia di persistenza del dato tra uno shutdown e il successivo riavvio della macchina.
La creazione di una VM comporta anche la creazione di un cosiddetto Cloud Service che, in parole povere, in questa prima fase può essere ridotto ad un nome DNS nella forma [nome].cloudapp.net. Questo sarà il nome DNS pubblico tramite il quale sarà possibile accedere alla macchina virtuale e, previa apertura del firewall, il nome al quale ci potremo collegare per i servizi di RDP o HTTP/FTP/SQL.
Gestione dei VHD
In WA possiamo gestire al 100% i dischi VHD collegati a una macchina virtuale. Essendo IaaS, la cosa non ci sorprende; è anche possibile fare l’upload di un disco VHD da locale al datacenter di WA, per poi collegarlo ad una istanza in esecuzione. È possibile anche farlo per dischi primari, per esempio contenenti una installazione di Windows Server personalizzata e opportunamente “syspreppata”, oppure al contrario è possibile scaricare un intero VHD per eseguire la macchina in locale.
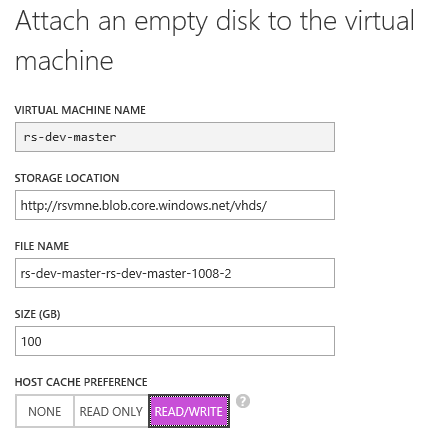
Un VHD può essere collegato in Read-Write solo da una macchina alla volta, mentre altre macchine possono collegarsi ad esso in sola lettura. Se si volesse raggiungere lo scopo di uno storage condiviso, occorre trovare una strategia alternativa, per esempio basata su una share di rete accessibile da una macchina all’altra, per esempio tramite percorso UNC.
Dimensioni delle macchine
Siamo partiti dallo IaaS perché, pur essendo dal punto di vista di chi scrive solo un aspetto secondario dell’ecosistema in questione, esso rappresenta le fondamenta su cui poggiano tutti gli altri servizi e come tale, detta alcune delle regole del gioco, per esempio le dimensioni di tutte le possibili istanze a disposizione su tutta la piattaforma. In WA una istanza può essere una di queste:
Tabella 1 - Le dimensioni più comuni delle istanze di Windows Azure.
|
VM Size |
CPU Cores |
Memory |
Bandwidth |
|
Extra Small |
Shared |
768 MB |
5 (Mbps) |
|
Small |
1 |
1.75 GB |
100 (Mbps) |
|
Medium |
2 |
3.5 GB |
200 (Mbps) |
|
Large |
4 |
7 GB |
400 (Mbps) |
|
Extra Large |
8 |
14 GB |
800 (Mbps) |
Di recente Microsoft ha introdotto nuove dimensioni di istanze, come la A5, A6 o A7 ma le dimensioni più utilizzate e comuni sono quelle nella tabella sopra. Sempre dalla tabella sopra, emerge un dato interessante: ogni istanza, eccetto la Extra-small,sono in un fattore di scala doppio l’una con la successiva
Un’ora di una istanza Medium corrisponde a 2 ore di calcolo, così come un’ora di XL corrisponde a 8 ore di calcolo. L’unica dimensione fuori scala è la XS, la cui ora corrisponde a 1/6 di ora di calcolo Small. La dimensione Extra-small è la dimensione consigliata per i test, viste le ridotte risorse e il core condiviso: tuttavia molti clienti la utilizzano anche per servizi di produzione, con particolare attenzione a non erogare servizi che fanno uso intensivo di banda, visto il “cap” di 5Mbps che è stato messo all’IO di rete.
Powershell
Sebbene quasi tutto l’ecosistema WA sia gestibile da remoto tramite una API REST su HTTP, è luogo comune utilizzare le cmdlets di Powershell per le operazioni di governance più comuni (che ne fanno uno strumento tipicamente utilizzato da chi sfrutta lo IaaS). Le estensioni di Powershell per Windows Azure permettono operazioni complesse direttamente da shell come, per esempio:
Per gli utenti avanzati di Powershell, la comodità non finisce qui ma si può incrociare, tramite il “pipe” ad una serie di altri comandi interessanti, fino a creare vere e proprie automazioni di gestione, tutto da riga di comando.

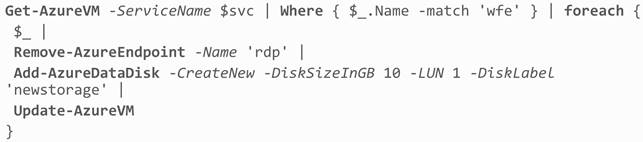
Per concludere, con WA possiamo quindi avere una serie di macchine virtuali pubblicamente accessibili, configurandone le caratteristiche e i servizi connessi. Alternativamente, possiamo avere delle macchine in un ambiente isolato, accessibile solo tramite VPN: in quest’ultimo caso, stiamo parlando di Virtual Networks.
Virtual Networks
Le reti virtuali di WA sono una astrazione che permettono il provisioning di machine virtuali in ambiente isolato con la possibilità di configurare puntualmente le varie subnet della rete, i server DNS al fine di replicare o migrare in Cloud una infrastruttura on-premise esistente: non le tratteremo tuttavia in questo articolo.
Costi di servizio
I costi delle Virtual Machines sono divisibili in:
- Costi di computazione: le ore di calcolo delle macchine, durante il periodo di “accensione”.
- Costi di storage: i costi per GB/mese dello storage persistente attaccato alle macchine.
- Costi di banda: i costi di banda “egress”, ovvero traffico verso l’esterno, che una macchina virtuale sostiene.
Alla luce di questa macro-divisione, i costi puntuali sono:
|
Nome istanza di calcolo |
Core virtuali |
RAM |
Prezzo all'ora |
|
Molto piccola (A0) |
Condivisa |
768 MB |
€ 0,01 |
|
Piccola (A1) |
1 |
1,75 GB |
€ 0,07 |
|
Media (A2) |
2 |
3,5 GB |
€ 0,13 |
|
Grande (A3) |
4 |
7 GB |
€ 0,27 |
|
Molto grande (A4) |
8 |
14 GB |
€ 0,54 |
Un elenco completo dei costi aggiornati di servizio è disponibile qui: http://www.windowsazure.com/it-it/pricing/details/virtual-machines/
Servizi di PaaS
Come accennato all’inizio di questo articolo, il punto di forza di WA è certamente l’offerta di Platform as-a Service, partendo da servizi accessori (anche se utilizzabili in maniera stand-alone) detti “building-blocks”, fino ad arrivare ai servizi principe dell’ecosistema, quelli per l’hosting di applicazioni e dati.
I servizi principali di WA sono:
- Web & Worker roles
- Web Sites
- SQL Database
- Storage
Web & Worker roles
L’obiettivo di un utente di WA è, il più delle volte, quello di distribuire la propria applicazione Web su un framework infrastrutturale dove poi essa potrà eseguire e scalare; alternativamente, un bisogno comune è quello di avere dei processi “batch” in esecuzione continua, finalizzati all’elaborazione di informazioni. Per soddisfare questo bisogno, il primo modello di deployment di WA è stato quello dei Web roles e Worker roles. Un “ruolo” è un contenitore di servizio dove incapsuliamo la nostra applicazione Web (o il nostro processo) affinché sia compatibile con il modello di esecuzione di WA. Se quello di cui abbiamo bisogno è solamente uno spazio dove fare girare la nostra applicazione Web, allora molto probabilmente ci sarà più utile il servizio Web Sites (trattato più avanti). Tuttavia, sempre in questa circostanza, utilizzare un Web role è molto semplice: a partire infatti da un qualsiasi progetto web Visual Studio, previa installazione dell’SDK per WA, si può creare un progetto contenitore (il ruolo appunto) per la nostra applicazione.

Una volta creato un progetto wrapper, esso potrà tendenzialmente contenere da 1 a N ruoli, dove ogni ruolo rappresenterà un pool di macchine in un container di alto livello che chiamiamo, ancora una volta, Cloud Service.
Nella seguente figura c’è un esempio di composizione di ruoli: il progetto wrapper, che nel nostro caso si chiama WebApplication1.Azure, sarà caricato su WA su un particolare Cloud Service preventivamente creato; all’interno di esso ci saranno 3 ruoli, 2 ruoli web (le applicazioni WebApplication1 e WebApplication5) e 1 ruolo worker (il progetto WorkerRole1).
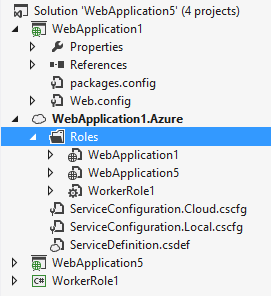
Gerarchicamente parlando, abbiamo:
- Un Cloud Service (talvolta detto Hosted Service)
- N ruoli per Cloud Service
- K istanze per ruolo
La figura seguente sintetizza il concetto:

Questo modello di esecuzione permette di avere un punto unico dove definire i vari “pezzi” del nostro servizio (i ruoli) per poi gestirne puntualmente lo scaling, ovvero la capacità di aumentare il numero delle macchine fisiche che eseguiranno ogni ruolo.
Per chi non fosse avvezzo ai concetti di scaling e di configurazioni web-farm, quello in figura sopra rappresenta un modello di esecuzione dove N macchine compiono le stesse operazioni, al fine di accettare una grande quantità di traffico in ingresso.
Scaling e stateless
Sarà capitato nei precedenti articoli di parlare di questi concetti, ma vale la pena di riprenderli e contestualizzarli sul prodotto che stiamo analizzando. Se il nostro sito web dovrà essere acceduto da milioni di persone, per quanto siamo stati bravi a svilupparlo secondo le migliori pratiche, prima o poi dovremo fare i conti con la saturazione delle risorse e, di conseguenza, il potenziamento della macchina su cui sta girando.
La storia informatica ci insegna però che non potremo mai aumentare le risorse indefinitamente perché questo ha un costo elevatissimo e dei limiti fisici: infatti non esistono comunque processori commerciali più potenti di una manciata di GHz, è raro e costoso mettere in piedi una macchina con centinaia di GB di RAM e così via. Per questo, negli ultimi tempi si è parlato sempre di più di scale-out, ovvero aumento delle risorse tramite affiancamento, piuttosto che di scale-up, aumento lineare delle risorse sulla singola macchina: lo scale-out quindi consiste nel prendere più macchine invece che potenziarne una.
Premesse le ovvie considerazioni sulla riduzione dei costi (due macchine di potenza X costano sensibilmente meno di una macchina di potenza 2X), questo modello di scaling abilita anche alcuni scenari di alta affidabilità: se infatti il nostro sito sta girando contemporaneamente su due o più macchine, al fallire di una, continuerà a girare (magari più lentamente) sulle macchine residue.
Tutto questo però è possibile solo sotto alcune condizioni, ovvero che le applicazioni Web che distribuiamo su queste macchine non siano dipendenti dallo stato della macchina. Se così fosse, per esempio quando una applicazione web scrive dati in RAM, allora una sola macchina su N “saprebbe” quello stato e, in caso di crollo, lo porterebbe nella tomba con sé. In ambito HTTP inoltre, ove una richiesta è sempre irrelata dalla precedente (protocollo stateless), un utente potrebbe, durante la stessa sessione di navigazione, incappare in un server per una prima richiesta e poi in un altro per una seconda richiesta. Nel caso l’applicazione Web salvi la sessione in memoria, come si comporterà il server della seconda richiesta? Esso semplicemente non avrà alcuna visibilità di ciò che è accaduto sul primo e quindi si comporterà come se quella richiesta (la seconda) fosse la prima. Questo concetto, semplicisticamente rappresentato nell’esempio, è il motivo per cui le applicazioni web disegnate per essere distribuite sul cloud e, in generale, in una Web Farm, devono essere stateless, ovvero indipendenti dallo stato. Nella pratica basti tuttavia sapere che l’indipendenza dallo stato si ottiene esternalizzandolo in un repository comune a tutti i nodi del cluster, ad esempio un database.
SLA e affidabilità
Visto che il modello dei ruoli prevede la ridondanza degli stessi, le operazioni di up-scale (aumento del numero di macchine) e down-scale (diminuzione) sono gestibili tramite un pannello e non generano sforzo per l’utente. In realtà, il processo di provisioning stesso dei server è completamente gestito da WA e l’utente “vede” soltanto la propria applicazione quando diventa online. Nel caso di più macchine a supporto dello stesso ruolo, l’utente vede sempre e solo un unico endpoint, quello del bilanciatore.
Il bilanciatore è un dispositivo in grado di smistare il traffico di rete da un punto di ingresso (che nel caso dei Cloud Services sarà un nome DNS del tipo [nome].cloudapp.net) a N endpoint, che saranno le nostre macchine ridondate. Questo sistema permette a noi utenti di poter registrare l’IP e l’indirizzo pubblico del servizio all’indirizzo del bilanciatore, sotto il quale Windows Azure potrà cambiare l’assetto fisico delle macchine a suo piacimento (anche per aggiornarle ai nuovi sistemi operativi o alle patch di sistema in modo trasparente).
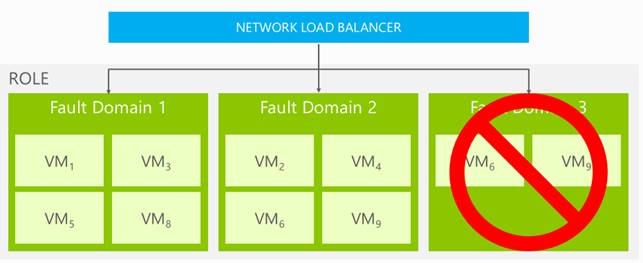
WA garantisce uno SLA del 99,95% sui Cloud Services, solo se l’utente ha almeno due macchine per ruolo. Significa che se l’utente ha distribuito la propria applicazione su almeno due macchine, WA effettuerà le operazioni di manutenzione sulle macchine in modo da garantire la continuità di servizio (upgrade domains) e isolerà le macchine in rack separati in modo da minimizzare la possibilità di incappare in un disservizio (fault domains).
Sviluppo .NET
Una macchina che esegue un Web Role è una macchina Windows Server con installato:
- Internet Information Services >= 7.x
- ASP.NET 3.5 SP1, 4.0 o 4.5
- PHP e FastCGI
Con un runtime del genere è possibile, senza ulteriori configurazioni, fare il deployment di una soluzione ASP.NET o PHP ed eseguirla nel ruolo. Per poter eseguire in locale la soluzione analogamente a come essa eseguirà sul ruolo, è possibile avviare il debug anche su un emulatore, facente parte dell’SDK ufficiale, che emula l’esecuzione nel cloud. Per tutte le necessità non direttamente gestibili con i runtime preinstallati sui ruoli, è possibile personalizzare le istanze tramite opportuni processi di avvio (startup tasks
All’inizio di questa parte abbiamo detto che per l’hosting di applicazioni Web è molto adatto il servizio Web Sites, cosa che troveremo valida proseguendo la lettura nella sezione apposita; allora mi chiederei: a cosa servono i Web & Worker Roles?
Un elenco delle risposte potrebbe essere questo:
- Per gestire le regole di firewall sulle macchine;
- Per eseguire applicazioni che hanno bisogno di runtime speciali da installare sulle macchine di destinazione;
- Per comunicare con WA (tramite API) e per innestare della logica negli eventi di ciclo di vita dell’applicazione su WA;
- Per avere il controllo completo (nel bene o nel male) sulle macchine di destinazione.
- Con le VM ci saranno più utenti che inoltreranno richieste di assistenza e, trattandosi di IaaS, sotto il controllo dell’utente, ci saranno sicuramente per Microsoft più problematiche da gestire.
- Ogni vendor serio di Cloud ha più interessa a spingere un servizio PaaS piuttosto che uno IaaS, per i benefici tecnologici che ne deriva. Incentivare quindi il passaggio al PaaS con una riduzione dei prezzi rispetto allo IaaS può essere una strategia per questa finalità.
- Lo storage dove carichiamo i binari e/o il contenuto dell’applicazione web
- Le macchine IIS che puntano a questo storage ed eseguono la soluzione, come fossero solamente “forza lavoro” disponibile on-demand.
- Free
- Shared
- Standard
- Un FTP (e il suo fratello maggiore più sicuro SFTP);
- Il meccanismo di Web Deploy, ovvero un meccanismo integrabile anche in Visual Studio per pubblicare le soluzioni direttamente da lì;
- La sincronizzazione DropBox, tramite un processo di trust tra WA e quest’ultimo;
- La sincronizzazione di un repository Git, anche questo tramite un processo minimale di configurazione del link;
- La pubblicazione TFS, ovvero un ulteriore link tra il servizio TFService (tfs.visualstudio.com) e WA. In questo caso è possibile utilizzare le eventuali competenze su TFS e sui meccanismi legati alle build per pubblicare automaticamente sotto alcune condizioni.
- IP-based
- SNI-based
- Blob storage
- Table storage
- Queue storage
- [nomeNamespace].blob.core.windows.net
- [nomeNamespace].table.core.windows.net
- [nomeNamespace].queue.core.windows.net
- Pubblico: tutti i blob al suo interno sono visibili senza autenticazione
- Privato: i blob sono accessibili solo con chiave
- Spazio occupato
- Banda consumata per fare “uscire” il dato dal datacenter
- Transazione, ovvero la singola operazione di accesso
- Windows Azure – http://www.windowsazure.com/en-us/
- Management Portal – https://manage.windowsazure.com
- Training Kit - http://www.microsoft.com/en-us/download/details.aspx?id=8396
Sotto almeno una di queste condizioni è consigliato affidarsi al modello di deployment dei Web & Worker roles; in caso contrario, ovvero nel caso in cui dobbiamo distribuire applicazioni web, per quanto complesse, che non abbiano di questi requisiti, allora consiglio di approcciare direttamente i Web Sites.
Costi di servizio
I costi di servizio dei Cloud Services (Web & Worker roles) sono facilmente riconducibili ai costi della macchine virtuali utilizzate per i deployment e seguono questa tabella:
|
Nome istanza di calcolo |
Core virtuali |
RAM |
Prezzo all'ora |
|
Molto piccola (A0) |
Condivisa |
768 MB |
€ 0,01 |
|
Piccola (A1) |
1 |
1,75 GB |
€ 0,06 |
|
Media (A2) |
2 |
3,5 GB |
€ 0,12 |
|
Grande (A3) |
4 |
7 GB |
€ 0,24 |
|
Molto grande (A4) |
8 |
14 GB |
€ 0,48 |
Rispetto ai costi delle VM, vediamo che c’è una leggera riduzione dei prezzi. Pur trattandosi delle stesse macchine, possiamo identificare due motivazioni:
Un elenco completo dei costi aggiornati di servizio è disponibile qui: http://www.windowsazure.com/it-it/pricing/details/cloud-services/
Web Sites
Il progetto Web Sites, che, come dice il nome stesso, è dedicato alla creazione di siti web nel cloud, nasce dall’esigenza di ridurre al minimo la conoscenza del PaaS sottostante una applicazione e dalla volontà di rendersi completamente indipendenti da tale PaaS dal punto di vista architetturale, per minimizzare quello che viene chiamato lock-in. Il lock-in è quel grado di “detenzione” che la nostra applicazione ha in un determinato ambiente di esecuzione: nel caso di un servizio di posta, il lock-in è misurabile in quanto semplice sia spostare la gestione della posta, gli utenti e le caselle su un altro fornitore; nel caso di un PaaS, il lock-in è misurabile in quanto impegno umano e tecnico ci vuole per migrare una soluzione su un altro PaaS.
Nel caso dei Web & Worker roles, benché minimo, c’è un grado di personalizzazione che le nostre applicazioni dovranno implementare per girare al meglio: è possibile infatti intercettare alcuni eventi di ambiente, utilizzare alcune API di WA e così via. Di per sé il meccanismo dei Cloud Services e dei progetti wrapper aggiungono solamente un layer di astrazione, senza imporci modifiche infrastrutturali, ma tendenzialmente qualsiasi cosa diversa dal “non far nulla” è di per sé una specializzazione.
A tal proposito, una situazione ideale consisterebbe nell’aver a disposizione uno spazio dove pubblicare la nostra applicazione, copiando semplicemente il contenuto della cartella degli “eseguibili” nel posto designato all’esecuzione. Web Sites abilita anche questo genere di scenari di deployment, mettendo in grado l’utente di andare online in pochi minuti: benchè il processo di “copia remota” possa far sorgere a qualcuno qualche dubbio (ricorda molto l’hosting e il concetto di spazio web), ovviamente il servizio non perde dei requisiti fondamentali di un PaaS cloud, come innanzitutto la capacità di scalare.
Prima di entrare nei dettagli del servizio, ci tengo a sottolineare che Web Sites non solo è il “Re dei PaaS”, per via del suo lock-in nullo e della sua caratteristica di zero-governance, ma è anche un sistema che, per le sue limitazioni (nessun accesso o modifica al sistema operativo), favorisce le best-practices e la manutenibilità delle soluzioni.
Senza peccare di semplicismo, si può affermare che, se una applicazione Web ha bisogno di particolari tweak del sistema operativo, probabilmente è soggetta a qualche problema architetturale. Nella maggior parte delle ipotesi infatti, il software Web dovrebbe essere isolato e non dipendere dalle caratteristiche della macchina poiché, in caso di scaling o di semplice manutenzione, sarebbe più difficile ricostruire la situazione originale su una nuova macchina di destinazione. È più corretto sviluppare una soluzione che possa eseguire su qualsiasi server con IIS e .NET Framework, piuttosto che una soluzione scritta per funzionare solamente in presenza di una determinata patch di sicurezza del SO, oppure di un particolare runtime. In questo caso comunque, seppur meno “pulita” dal punto di vista architetturale, è sempre una soluzione distribuibile su un Web role.
Runtime e Livelli di servizio
Web Sites è un servizio che possiamo immaginare composto da due elementi:
IIS è configurato per eseguire applicazioni .NET, ASP Classico, PHP o Node.js.
Web Sites esegue in tre modalità:
Quando si crea uno spazio su Web Sites (d’ora in poi WAWS), come in figura:
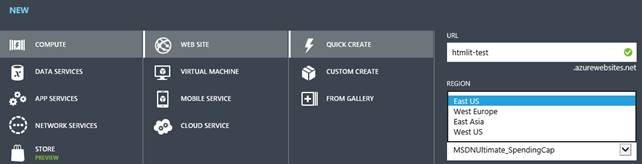
si specifica solamente la zona. Il sito sarà inizialmente in modalità free (poiché gratuita) ma lo potremo portare al livello “Standard” in qualsiasi momento, tramite il selettore apposito nella sezione dedicata allo scaling.
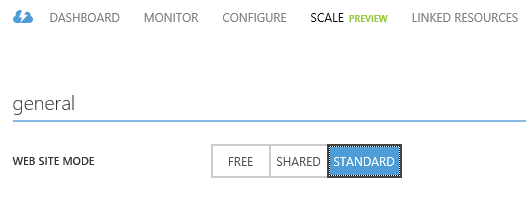
Quando portiamo un sito al livello standard, ci viene anche proposto il numero di istanze che dovranno eseguirlo e, in presenza di altri siti nella stessa regione, essi verranno tutti installati sul pool di macchine dedicate del livello standard. Sebbene sia più logico poter scegliere quali siti eseguano in modalità standard e quali no, anche nella stessa zona, questo non è al momento possibile.
Considerato che la minima spesa per il servizio Standard, corrisponde ad una istanza Small, dovremo fare un calcolo se il costo previsto conviene e, nel caso, ottimizzare l’utilizzo del servizio massimizzando il numero di siti installati: infatti, su un servizio Standard, è possibile installare fino a 500 siti contemporaneamente e sarà WA a gestirne la divisione logica e l’isolamento virtuale a runtime.
Infine, nei Web Sites è anche possibile creare un nuovo sito a partire da un template, da scegliere nella Gallery, ovvero una elenco di applicazioni pre-installate dal CMS alla soluzione di e-Commerce fino al blog WordPress e così via.
Deployment
Indipendentemente dal livello di servizio scelto, il deployment di un sito su WAWS è un’operazione analoga alla copia remota. Possiamo sfruttare:
Sebbene la prima modalità o la seconda siano le più semplici, con le altre modalità il servizio Web Sites integra anche un controllo delle versioni delle applicazioni, utile per poter controllare in qualsiasi momento quale versione è pubblicata ed eventualmente poter fare rollback velocemente di uno o N changeset precedenti.
Impostazioni e SSL
All’interno della pagina di un servizio su WAWS abbiamo alcune preziose (ma poche) impostazioni su cui lavorare. Prima tra tutte la possibilità di associare un certificato SSL al nostro sito, in due modalità:

Costi di servizio
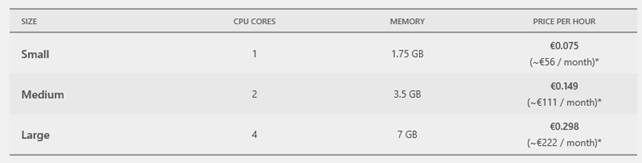
I costi legati al servizio Web Sites sono anch’essi facilmente riconducibili, nel caso del livello di servizio Standard, ai costi della macchine virtuali (con qualche lieve differenza):
Infine, il servizio SSL ha un costo, dipendentemente alla tipologia IP o SNI che vogliamo utilizzare:

Un elenco completo dei costi aggiornati di servizio è disponibile qui: http://www.windowsazure.com/en-us/pricing/details/web-sites/.
Autoscaling
Uno dei presupposti del Cloud Computing è, come abbiamo visto, che i servizi offerti siano effettivamente tariffati a consumo, nell’ottica on-demand; l’altro punto fondamentale per chi sceglie cloud è la possibilità di far scalare le proprie soluzione con relativa semplicità.
Nelle prime versioni di Windows Azure esistevano solo i Cloud Services (già Hosted Services), che permettevano lo scale-out tramite pannello di controllo e file di configurazione: era infatti possibile, in pochi click, aumentare o diminuire le macchine virtuali allocate ad una soluzione, incrementando di fatto la portata di carico dell’intero servizio. Negli ultimi tempi, grazie alla maturità acquisita da Windows Azure e dopo numerose richieste da parte degli utenti, Microsoft ha introdotto la funzionalità di Autoscaling, che permette di aumentare o diminuire le macchine virtuali di un servizio in modo automatico, in base al carico reale di una applicazione.
È infatti vero che, nonostante fosse sempre stato possibile fare up-scaling o down-scaling, esso era un processo manuale e poteva non recepire correttamente le richieste reali di carico. Nel caso infatti il sistema stia sperimentando un picco improvviso, è molto probabile che l’utente se ne accorga molto dopo del sistema stesso, che invece ne risulterebbe già congestionato nei primi attimi. Per questo motivo gli utenti di WA hanno sempre cercato un rimedio a questo problema, introducendo talvolta dei complicati meccanismi di auditing e monitoring che permettessero all’applicazione di “conoscere” lo stato del sistema e, tramite le API di amministrazione, di allocare/disallocare macchine. Uno dei componenti più importanti sviluppati in questo senso, è stato WASABi (Windows Azure Autoscaling Application Block), il cui contro però era l’eccessiva configurazione e una complessa articolazione, seppur tavolta molto utile, delle funzionalità.
WASABi è un componente ancora molto usato, ma per le necessità più comuni, ovvero per gestire lo scaling automatico in caso di saturazione delle risorse fisiche della macchina (CPU, per esempio), Windows Azure ha messo a disposizione, sia per i Cloud Services che per i Web Sites, la funzionalità di autoscaling, configurabile direttamente da pannello di controllo.
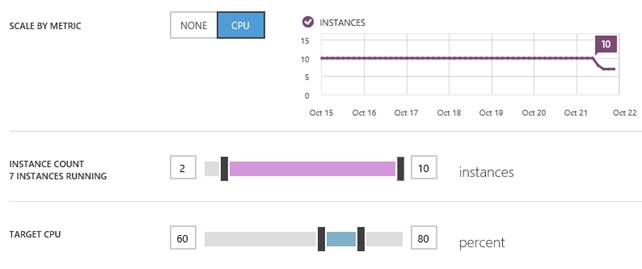
L’autoscaling entra in gioco grazie all’impostazione di due indicatori nello slider “Target CPU”. Nella figura sopra stiamo indicando che se la media di utilizzo CPU sale sopra l’80%, aumenteremo il numero delle istanze; se, analogamente, tale indicatore scenderà sotto la soglia di 60, potremo toglierle. Possiamo chiaramente anche decidere di quante istanze può oscillare l’autoscaling, con l’impostazione dello slider “Instance Count”.
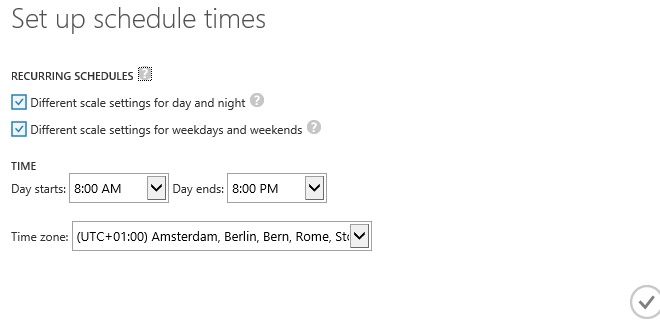
Scheduled times
È possibile anche definire una finestra speciale per particolari momenti della settimana tipo, in modo da favorire una determinata logica di autoscaling in luogo di una specifica, per esempio per il weekend.
Autoscaling su coda
Nel caso dei Cloud Services, l’autoscaling può essere configurato con una modalità aggiuntiva, rispetto a quella basata sul controllo della CPU. Se per esempio in un Cloud Service abbiamo un Worker Role che processa i messaggi di una coda, non è detto che al crescere dei messaggi cresca l’utilizzo della CPU ma sicuramente crescerà il tempo totale che N istanze impiegheranno per smaltirli. Per questo motivo è possibile stabilire dei trigger di autoscale in funzione del numero massimo di elementi che risiedono su una coda:
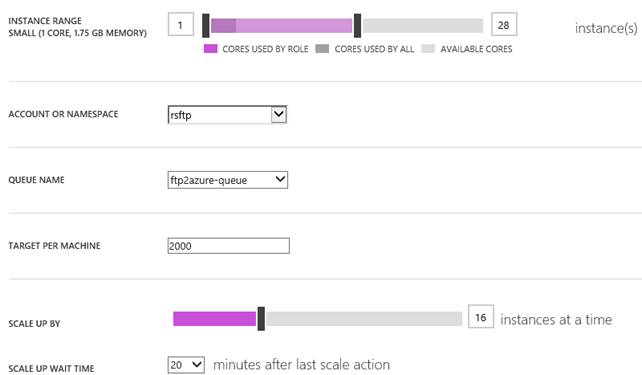
Nel caso sopra, stiamo indicando al sistema di aumentare di 16 istanze la soluzione, nel caso le istanze correnti non riescano a far stare la coda ftp2azure-queue sotto i 2000 elementi.
Storage
Il servizio di Storage è un servizio utilizzabile sia da parte di altri servizi distribuiti su WA, sia da locale o da sistemi on-premise e infine è anche il servizio che WA stesso utilizza per fornire alcuni servizi chiave (come il salvataggio dei VHD per le VM).
Il servizio di storage consiste in realtà di tre sotto-servizi; per ogni “account”, che possiamo chiamare piuttosto un contenitore o un namespace, abbiamo:
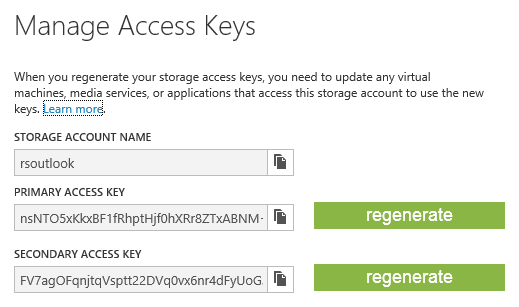
Quando un utente accende un nuovo namespace di storage (la terminologia corretta è “account”, ma usiamo namespace per non fraintenderlo con l’Account inteso come sottoscrizione a WA), si hanno subito a disposizione le tre URL dei rispettivi servizi:
Le entità (blobs, tables, queues) dei vari endpoint saranno accessibili tramite lo stesso URL in profondità di path, utilizzando HTTP per le letture/scritture.

Per ogni namespace/account di storage, esiste una coppia di chiavi di autorizzazione da allegare alle richieste per controllare l’endpoint. Ne esiste una coppia perché, avendo la possibilità di rigenerarle una ad una, possiamo utilizzarne una per l’ambiente “sicuro” e l’altra per un ambiente un po’ più lasco (ad esempio da condividere con un team) e poi rigenerarla all’occorrenza.
Blob storage
Il blob storage organizza al suo interno i contenuti assegnando un URL ad ogni risorsa. Un elemento top-level di un endpoint di blob storage si dice “container”. Un container è un contenitore di blob e può essere:
Esiste anche una terza modalità, declinazione della prima, che consente ad un container di essere “talmente pubblico” da poterne anche interrogare i metadati relativi al contenuto (un analogo del “list content permission”).
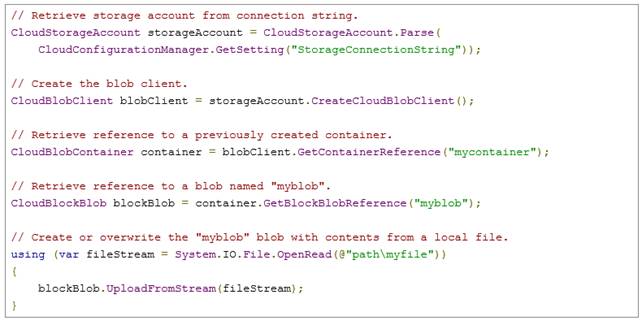
Dal codice .NET, scrivere sul Blob storage è una operazione semplice, grazie alla libreria dell’SDK .NET.
Il blob storage non supporta il concetto di cartelle, ma solo di container di alto livello. Questo significa sia che non possiamo creare cartelle all’interno di un container, sia e soprattutto che non possiamo assegnare permessi granulari a profondità arbitraria dei percorsi su di esso. Un url così, infatti:
http://teststorage.blob.core.windows.net/mycontainer/public/test/doc.txt
Significa che, all’interno dell’account/namespace teststorage, c’è un container mycontainer che ha un blob public/test/doc.txt: questo ci suggerisce che nonostante non esista il concetto di cartella, un blob può avere un qualsiasi nome composto da “/” e che dia quindi la percezione all’utente di essere in presenza di una alberatura simile al FileSystem.

Table storage
Nel table storage è possibile definire delle tables, al cui interno saranno memorizzate delle rows. La particolarità di queste righe tuttavia è che, al contrario di un database relazionale, ogni riga potrà avere uno schema proprio, anche arrivando ad un caso volutamente provocatorio come quello in tabella:
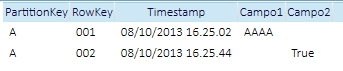
Il beneficio del table storage è quello di avere uno storage scalabile e ad alte performance, per dati non relazionali (tipicamente gli stessi che metteremmo in un noSQL key-value) oppure dati esprimibili come entità uniformi ma prive di vincoli relazionali o di integrità tipici del mondo RDBMS: un esempio d’uso può essere utilizzarlo come backend di collezioni di entità provenienti da una sorgente a oggetti.
Shared Access Signature
Benché esistano le chiavi per regolare l’accesso allo storage, è molto comune la necessità di mettere a disposizione di un cliente o di una applicazione solo un certo container o un certo blob (nel caso del Blob storage). Questa operazione è possibile grazie alle Shared Access Signature, ovvero dei token, generati opportunamente su un container o su un blob che incapsulano l’informazione di accesso granulare e limitato nel tempo. Questo meccanismo consente di raggiungere un blob in un container privato tramite un URL più complesso ma condivisibile, a differenza della chiave di accesso che, oltre a non essere comoda da condividere, rappresenta un rischio globale per la sicurezza di tutto lo storage account.
Costi di servizio
Lo storage ha un modello di costo basato su:
Il tutto secondo questa tabella:
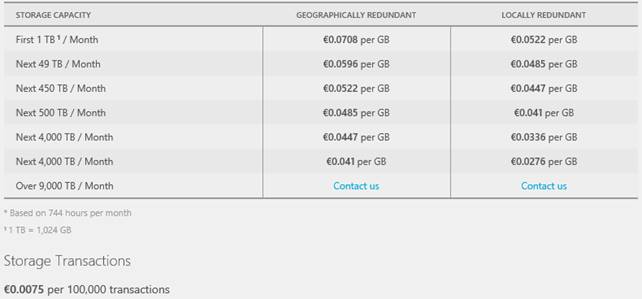
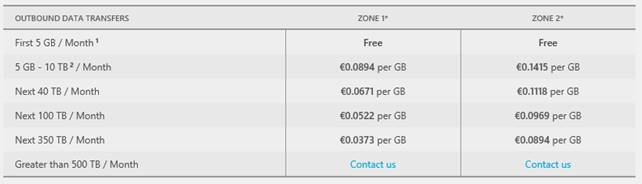
Un elenco completo dei costi aggiornati di servizio è disponibile qui: http://www.windowsazure.com/en-us/pricing/details/storage/.
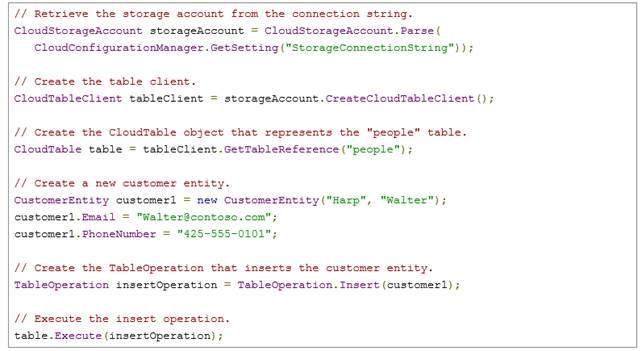
SQL Database
SQL Database è uno dei servizi più semplici di WA. Esso (d’ora in poi WASD) offre una astrazione remota di un database SQL Server, con un ridotto set di funzionalità e, ovviamente, zero-governance. La potenzialità di SQL Database risiede nell’essere collocato in una infrastruttura di alta affidabilità e disponibilità, a carico di Microsoft che ne garantirà lo SLA e il disaster recovery.
Per creare un database WASD è necessario prima creare un contenitore, detto “server”: la dicitura è impropria, perché il nostro “server” è solamente un contenitore virtuale di N database WASD, in co-location con altri N container di altri clienti. WASD è infatti una infrastruttura condivisa che, pur garantendo la replica e l’affidabilità, approccia la gestione delle risorse in una ottica best-effort.
Una volta creato un DB WASD esso si presenterà all’utente come un banale endpoint TDS, aperto sulle porte standard di SQL Server e fornito di una connessione cifrata per evitare lo sniffing dei pacchetti. Ci dobbiamo ricordare infatti che, nel caso stessimo testando le nostre soluzioni da “fuori”, ovvero fuori dal datacenter di Microsoft, ogni connessione (anche di test) è conseguita lungo tutta l’internet pubblica necessaria per arrivare a destinazione.
Dal punto di vista delle nostre applicazioni, non ci sarà differenza tra l’operare con SQL Server e WASD: in .NET potremmo utilizzare ADO.NET e quindi Entity Framework senza alcun problema di incompatibilità e così anche per gli altri provider. L’unica regola da seguire, per comprendere cosa non sia supportato in WASD, è quella di escludere tutto ciò che dipenda dal FileSystem o dalla topologia fisica dell’installazione di SQL Server: in quel caso, non essendo possibile in nessun modo operare su queste impostazioni, tutte le funzionalità che direttamente o indirettamente ne fanno uso, sono escluse.
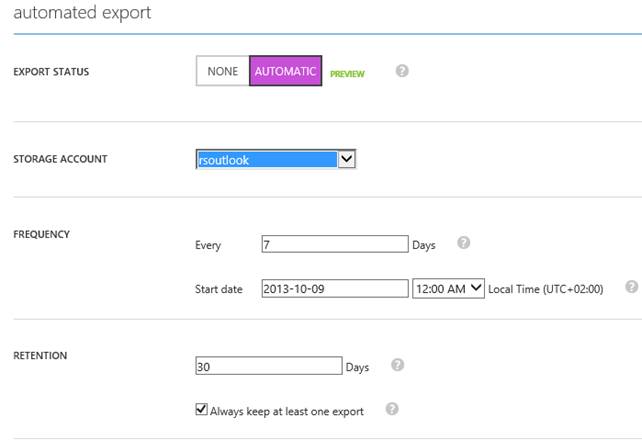
Backup automatici
Nella sezione precedente abbiamo trattato lo storage, vera pietra miliare di tutti i servizi di WA. Su di esso si basa anche il servizio di backup automatici e pianificati di WASD, accessibile tramite una tab del pannello del database. Questo servizio consente di pianificare dei backup con finestra di ritenzione, che WA gestirà autonomamente e salverà su un opportuno storage account specificato. Il formato di salvataggio è un BACPAC, non trattato in questo articolo, ma che consigliamo di approfondire separatamente: basti comunque sapere che un BACPAC è un formato di backup completamente portabile e, a differenza dei formati .BAK, esso può essere importato trasversalmente alle versioni di SQL e, senza problemi, anche a partire da SQL Server 2005.
Servizio Premium
Di recente è stato introdotto un livello di servizio, ancora in preview, denominato “Premium”. In questo livello di servizio è possibile riservarsi alcuni slot di risorse da assegnare ai nostri database WASD, in modo da poter erogare delle performance predicibili alle applicazioni che ne fanno uso. È molto importante capire lo scopo di questo livello di servizio; non è una modalità di “boost” delle performance bensì una modalità in cui, a differenza del modello standard in cui le risorse sono condivise tra N clienti e quindi soggette a fenomeni di limitazione o taglio, sappiamo con certezza che il “cap” a noi assegnato è una quantità stabilita: facciamo un esempio.
Database standard
Al tempo T1 abbiamo un database A che riceve connessioni e query tali da occupare di media una CPU completa e 1GB di RAM. In un imprecisato momento T2 arrivano sullo stesso cluster altre connessioni impegnative ad un altro database (magari di un altro cliente) e, benchè sul cluster ci siano molti processori e molta RAM, la connessioni e le query al database A cominciano ad essere interrotte o rallentate (throttling) dal sistema. Fino a T3 quindi, le applicazioni che usano il database A saranno più lente, fino a quando torneranno a livelli di performance come al solito. In T4 le risorse del cluster si liberano più della media e WASD alloca al database A due CPU e 2GB di RAM, con il conseguente raddoppio delle performance delle applicazioni ad esso collegate (non è mai così lineare, perdonate l’esempio).
Database premium
Con un database Premium, allochiamo staticamente un minimo garantito che il nostro DB avrà a disposizione. Questo significa che se questo minimo sarà sempre maggiore dal massimo carico al database, noi avremmo performance sempre predicibili a parità di condizioni. Una particolarità del database premium è anche quella di evitare il taglio delle connessioni, fenomeno decisamente fastidioso in alcuni ambiti dove non è sempre possibile ricorrere a policy di re-iterazione.
Data Sync
Data Sync è un servizio per sincronizzare in tutto o in parte i dati di uno o più database WASD e uno o più database SQL Server on-premise tra loro. La sincronizzazione non è da intendersi una replica, bensì un layer applicativo che, al verificarsi di modifiche o entro certe finestre di aggiornamento, iniziano un allineamento reciproco dei dati. Spesso, su fonti Microsoft, si parla di Data Sync come Synchronization-as-a-Service, visto il chiaro riferimento al modello del Microsoft Synchronization Framework.
Il wizard di Data Sync permette di definire una o più sorgenti dati on-premise: tali sorgenti, per essere raggiungibili dal servizio internet senza interventi tecnici sulla rete, dovranno installare un agente attivo che manterrà una connessione con il servizio centrale, detto HUB. L’hub è un database WASD (unico requisito di tutta l’architettura) che potrà essere sia il fruitore dei dati on-premise che il fornitore di essi. È infatti una specifica successiva, quella di definire come debba funzionare la sincronizzazione e, in caso di conflitti, chi vinca. Prima di procedere con l’implementazione di Data Sync, è necessario sapere che la soluzione fa uso di Trigger e che in ogni caso non può sincronizzare modifiche allo schema: il mapping di ciò che deve essere sincronizzato avviene infatti staticamente a configuration-time e non è soggetto a modifiche automatiche in seguito a cambiamenti della struttura dei dati.
Costi di servizio
WASD è, relativamente al servizio erogato, uno dei servizi più convenienti di WA. Infatti con la versione standard viene tariffata solo la dimensione del database, ai costi della tabella sotto:

Cambia tutto invece con il servizio Premium che, benchè sia ancora in preview, ha dei costi decisamente diversi, come in tabella:

Ovviamente i costi dei backup incorrono nel consumo di storage e quindi si fa riferimento alle tariffe per GB discusse precedentemente.
Conclusioni
In questo articolo abbiamo trattato la maggior parte dei servizi connessi alla piattaforma Windows Azure, con particolare insistenza sulle tematiche relative ai servizi PaaS, come i Cloud Services e i Web Sites. Abbiamo inoltre affrontato le Virtual Machines (IaaS) e i servizi legati ai dati (WASD, Storage, etc).
Riferimenti
