
Nell'articolo L'ottimizzazione dei documenti XML in Java sono state descritte le esigenze che hanno portato alla richiesta di ottimizzare i documenti XML (eXtensible Markup Language), introducendo i principali approcci alla risoluzione del problema. Il W3C (World Wide Web Consortium) ha emesso le specifiche per il formato binario di scambio EXI (Efficient XML Interchange), rappresentazione molto compatta delle informazioni XML. Questo formato è arrivato alla versione 1.0 ed entrato a far parte delle raccomandazioni W3C nel marzo del 2011.
La specifica ha dato origine a diverse implementazioni, in questo articolo esamineremo EXIficient, progetto open source avviato dalla Siemens AG e scritto nel linguaggio di programmazione Java. Muoveremo i primi passi nell'utilizzo del framework, vedremo cosa è incluso nella distribuzione del prodotto e come realizzare una classe Java che utilizzi la libreria EXIficient.
Utilizzeremo del codice di esempio per l'utilizzo delframework, per provarlo bisogna avere correttamente installato il JDK in versione 1.5 o successiva (requisito minimo per EXIficient). Nell'archivio allegato all'articolo è possibile trovare le classi che verranno successivamente descritte e un documento XML d'esempio corredato dal relativo XSD.
EXIficient: primi passi
EXIficient è un'implementazione della specifica EXI. Obiettivo finale è da un lato migliorare le performance degli strumenti che già utilizzano l'XML per scambiare dati, dall'altro permettere di incrementare il numero di domini e applicazioni per i quali l'XML rappresenti una scelta valida; tra gli obiettivi degli sviluppatori di EXIficient vi è inoltre l'intenzione di rendere la tecnologia disponibile alla comunità web.
Il progetto è arrivato alla versione 0.9.2. Il sito di riferimento mette a disposizione le informazioni essenziali; nella sezione download è possibile trovare il link del progetto su SourceForge, inoltre, sono disponibili le informazioni utili ad includere il progetto come dipendenza al POM maven, o per effettuare il checkout da un repository SVN. Potete continuare a leggere l'articolo anche senza avere familiarità con questi termini, basterà sapere che si tratta di strumenti a supporto del ciclo di vita del software, non indispensabili per utilizzare EXIficient. Sempre sul sito ufficiale, sezione "External Tools", è possibile trovare una lista di tools basati su EXIficient o che ne usano la libreria; tra questi tools vi è ExiProcessor, programma (in fase di sviluppo) utilizzabile da linea di comando che codifica e decodifica file XML verso e da files binari EXI, in pratica un'interfaccia testuale per il framework.
L'archivio bundle
Sempre tramite SourceForge è possibile scaricare l'archivio "exificient-[vers]-bundle". Al suo interno si potranno trovare le cartelle con sorgenti e binari, una cartella "lib" contenente la libreria exificient.jar e le altre librerie richieste come dipendenze (xercesImpl.jar e xml-apis.jar), una cartella "doc" con la documentazione e una cartella "sample-data" con un documento XML e il relativo schema XSD utili a effettuare le prime prove.
Sono inoltre disponibili due script, uno per Windows (run-sample.bat) e uno per Linux (run-sample.sh) che permettono di cominciare a usare l'archivio estratto come strumento di ottimizzazione.
E' possibile importare nell'IDE Eclipse, o in altri IDE come NetBeans, la cartella "bundle" come progetto esistente per lavorarci direttamente. In questa sezione ci limiteremo ad usare gli script.
EXIficient: utilizzo tramite script
Abbiamo visto che nell'archivio sono già disponibili gli script da lanciare, essi sono configurati per ottimizzare il file notebook.xml presente nella cartella "sample-data". Esplorando uno degli script, vedremo che per lanciare la classe EXIficientDemo vengono passati tre parametri, ossia il file da ottimizzare, lo schema XML associato e il numero di esecuzioni dell'ottimizzazione (di default una sola)
Lanciando lo script, otterremo il seguente output:
Esecuzione dello script run-sample
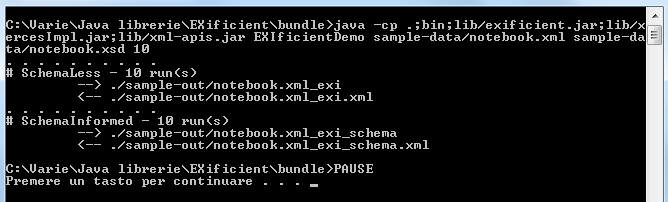
Verra quindi creata una nuova cartella, "sample-out", dove verranno posizionati i file ottimizzati e i file decodificati ottenuti a partire dai file codificati. E' possibile notare che inizialmente è stata effettuata una ottimizzazione senza l'utilizzo delle informazioni dello schema (SchemaLess) che ha prodotto un file (notebook.xml_exi) del peso di poco più di un terzo dell'originale, documento che è stato successivamente decodificato (notebook.xml_exi.xml) per riottenere l'XML di partenza.
In seguito si è ripetuta l'operazione aggiungendo il contributo dello schema XSD (SchemaInformed) ottenendo un file (notebook.xml_exi_schema) circa cinque volte meno ingombrante dell'originale. Come in precedenza, il file ottenuto è stato a sua volta decodificato per ottenere l'XML di partenza (notebook.xml_exi_schema.xml). Al variare del terzo parametro non sono registrate delle variazioni, è possibile mantenerlo al valore di default.
Proviamo a comprimere un altro documento XML. A tal scopo è possibile aggiungere alla cartella "sample-in" il documento XML con relativo schema inclusi nell'archivio allegato all'articolo (SampleGeospatialReference.xml e SampleGeospatialReference.xsd), per poi modificare lo script in modo che venga ottimizzato quest'ultimo documento.
Esaminando l'XML in questione, potremo vedere che si tratta di un esempio basato su classici dati di geolocalizzazione in cui vengono ripetute lunghe sequenze di elementi dello stesso tipo, in questo caso punti identificati da latitudine e longitudine. Modifichiamo ed eseguiamo lo script per caricare i nuovi documenti (di seguito si modifica lo script ".bat", nello stesso modo è possibile modificare per linux lo script ".sh"):
java -cp .;bin;lib/exificient.jar;lib/xercesImpl.jar;lib/xml-apis.jar EXIficientDemo sample-data-ext/SampleGeospatialReference.xml sample-data-ext/SampleGeospatialReference.xsdIn questo caso, come era da attendersi, per dati di geolocalizzazione i risultati sono anche migliori, arrivando ad ottenere un file ingombrante meno di un sesto dell'originale nella modalità SchemaLess, e circa un decimo dell'originale nella modalità SchemaInformed. I risultati offerti dal framework sono dunque in linea con quanto riportato sulle specifiche del formato EXI.
Finora abbiamo utilizzato lo script e la classe demo d'esempio, cosa succede però nel momento in cui vogliamo provare a ottimizzare un documento senza avere il corrispondente schema? Provando a passare solo il primo argomento (nome e posizione dell'XML) verremo informati… che non è stato fornito lo schema e il programma si arresterà sollevando un'eccezione (Input files not valid!). Questo succede perché la classe cui fa riferimento lo script richiede come ingressi sia l'XML che lo schema relativo.
Nella prossima sezione vedremo come utilizzare EXIficient in maniera programmatica, lavorando anche in assenza dello schema e arrivando alla creazione di una classe che potrà affiancare (o sostituire) la classe d'esempio messa a disposizione dagli sviluppatori del framework.
Utilizzo di EXIficient in programmi Java
È possibile importare la cartella bundle come progetto Eclipse. Così facendo potremo lavorare sulla classe d'esempio inclusa nel progetto per fare un po' d'esperienza con gli strumenti messi a disposizione ed estendere il comportamento della classe, ad esempio permettendo di ottimizzare documenti privi di schemi, o decidendo se adottare o meno opzioni come la compressione EXI.
Importazione del progetto, la classe EXIficientDemo
Importiamo il progetto bundle nell'IDE utilizzato (in Eclipse: File->Import…->Existing Projects into Workspace). Avremo quindi una situazione analoga a quella riportata nella figura seguente:
EXIficient – il progetto d'esempio
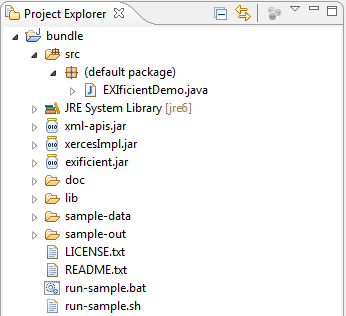
Sono facilmente riconoscibili la libreria EXIficient (e le librerie non native da cui dipende), le cartelle origine e destinazione dei dati, gli script d'avvio e soprattutto la classe d'esempio EXIficientDemo che mostra un esempio di utilizzo del framework.
Da un'analisi della classe avremo la conferma che per ottimizzare un XML è obbligatorio fornire il corrispondente XSD (verificare le condizioni presenti nel metodo parseAndProofFileLocations), e che le operazioni svolte sono indipendenti rispetto al variare del parametro runs.
Il nucleo della classe è formato dai metodi codeSchemaLess e codeSchemaInformed contenenti le invocazioni utili a definire come avverrà l'ottimizzazione e successivo ritorno all'XML originale, e i metodi encode e decode nei quali avvengono le operazioni effettive.
Eseguendo questa classe impostando i parametri d'ingresso (in Eclipse: Run as->Run configuration…->Arguments), si otterrà lo stesso effetto dell'esecuzione dello script "run-sample" (il cui scopo è esattamente quello di richiamare questa classe). Da notare che codifica e decodifica avvengono per mezzo delle API SAX.
Portando sotto IDE il progetto appena estratto, non sarà presente la cartella "sample-out", che verrà automaticamente creata eseguendo lo script o eseguendo il main EXIficientDemo fornendo in input i parametri di ingresso come da script (sample-data/notebook.xml sample-data/notebook.xsd)
Se non ancora presenti, è possibile includere nella cartella "sample-data" l'XML incluso nell'archivio allegato all'articolo e il relativo schema (SampleGeospatialReference).
Come abbiamo già visto in precedenza, la classe d'esempio presenta diverse limitazioni, procederemo pertanto alla realizzazione di una nuova classe con la quale esercitarci e ottenere una libreria in grado di fornirci un supporto maggiore.
La classe EXIficientUtilities
Realizziamo una nuova classe EXIficientUtilities che potremo utilizzare come classe d'accesso alla libreria EXIficient per ottimizzare files senza le restrizioni che abbiamo trovato nella classe Demo. Lavoreremo in due passi, nel primo ci limiteremo a prevedere la possibilità di ottimizzare anche documenti senza che venga fornito lo schema (classe EXIficientUtilitiesStep1). In seguito prevedremo la possibilità di impostare qualche altro parametro (classe EXIficientUtilities). E' possibile trovare entrambe le classi nell'archivio associato all'articolo. Si ipotizza che le classi vengano realizzate nel default package, in modo da riflettere l'organizzazione della classe Demo già presente (riducendo al minimo i cambiamenti da apportare agli script).
Nel primo passo il nucleo della classe, i metodi per la codifica e la decodifica (codeSchemaLess, codeSchemaInformed, encode e decode) restano invariati rispetto all'originaria classe Demo. Quello che cambia è in particolare il metodo parseAndProofFileLocations:
private boolean parseAndProofFileLocations(String[] args) throws Exception {
if (args.length != 0) {
if (args.length == 1) {
schemainformed = false;
xmlLocation = args[0];
}
if (args.length == 2) {
schemainformed = true;
xmlLocation = args[0];
xsdLocation = args[1];
}
} else {
schemainformed=true;
xmlLocation = "sample-data/notebook.xml";
xsdLocation = "sample-data/notebook.xsd";
}
// xml
File xmlFile = new File(xmlLocation);
xmlName = xmlFile.getName();
if (schemainformed) {
// xsd
File xsdFile = new File(xsdLocation);
if (xmlFile.exists() && xsdFile.exists()) {
File outputDir = new File(OUTPUT_FOLDER);
outputDir.mkdirs();
}
} else {
if (xmlFile.exists()) {
File outputDir = new File(OUTPUT_FOLDER);
outputDir.mkdirs();
}
}
return schemainformed;
}Al contrario di quanto avveniva in precedenza, il metodo che verifica gli argomenti di ingresso permette di utilizzare la classe anche nel caso in cui non venga passato lo schema. Inoltre, nel caso in cui non vengano forniti argomenti di ingresso, viene ottimizzato l'XML di default (o altro XML ivi specificato, funzionalità utile più che altro in fase di sviluppo). Il metodo ritorna una variabile booleana (schemainformed) che permetterà al main di accedere o meno alla sezione "schema-informed" (codeSchemaInformed). Sarà ora possibile eseguire la classe fornendo in ingresso solo l'argomento sample-data/notebook.xml.
Nella prossima (ed ultima) parte di questa trattazione analizzeremo le opzioni EXI in grado di influenzare direttamente le fasi di codifica e decodifica.
Le opzioni EXI
La specifica EXI presenta una serie di opzioni specificabili nell'header che consentono di variare il comportamento in fase di codifica/decodifica. Ad esempio è possibile attivare la compressione EXI, o variare il comportamento in corrispondenza di eventi quali commenti e prefissi del namespace.
EXIficient implementa le opzioni previste dalla specifica. Allo stato attuale (0.9.2) presenta le seguenti opzioni:
| Opzione | Descrizione |
|---|---|
| Fidelity Options | usate con lo scopo di abilitare o disabilitare la capacità di preservare certi tipi di informazioni (ad esempio prefissi del namespace o commenti). |
| Opzioni di allineamento | usate per controllare l'allineamento di codici d'evento e contenuto. Ad esempio, se settato su bit-alignment codici d'evento e contenuto associato sono compattati senza l'aggiunta di padding intermedio. E' l'opzione di default, funziona bene per messaggi di piccole dimensioni. Tra le alternative, vi è la possibilità di allineare sul byte invece che sul bit (opzione meno performante a causa del padding introdotto), o di abilitare la compressione EXI, opzione che per documenti di dimensione maggiore consente di compattare maggiormente le informazioni e risparmiare ulteriore spazio. |
| Strict mode | usabile in presenza dello schema per incrementare la compattezza tramite una interpretazione stretta dello schema e omettendo la presenza di determinati oggetti come prefissi del namespace. |
Abilitare la compressione EXI
Di seguito vedremo come abilitare la compressione EXI. A tal fine viene previsto un nuovo argomento per il main che consente di abilitare o meno la compressione stessa.
else if (args.length == 3) {
schemainformed = true;
xmlLocation = args[0];
xsdLocation = args[1];
exiCompression = Boolean.parseBoolean(args[2]);
}Le altre modifiche da apportare riguardano i metodi codeSchemaLess:
protected void codeSchemaInformed() throws Exception {
String exiLocation = getEXILocation(true);
EXIFactory exiFactory = DefaultEXIFactory.newInstance();
GrammarFactory grammarFactory = GrammarFactory.newInstance();
Grammars g = grammarFactory.createSchemaLessGrammars();//default
exiFactory.setGrammars(g);
if(exiCompression){
exiFactory.setCodingMode(CodingMode.COMPRESSION);
}
// encode
OutputStream exiOS = new FileOutputStream(exiLocation);
EXIResult exiResult = new EXIResult(exiFactory);
exiResult.setOutputStream(exiOS);
encode(exiResult.getHandler());
exiOS.close();
// decode
SAXSource exiSource = new EXISource(exiFactory);
XMLReader exiReader = exiSource.getXMLReader();
decode(exiReader, exiLocation);
} e codeSchemaInformed:
protected void codeSchemaInformed() throws Exception {
String exiLocation = getEXILocation(false);
EXIFactory exiFactory = DefaultEXIFactory.newInstance();
GrammarFactory grammarFactory = GrammarFactory.newInstance();
Grammars g = grammarFactory.createGrammars(xsdLocation);
exiFactory.setGrammars(g);
if(exiCompression){
exiFactory.setCodingMode(CodingMode.COMPRESSION);
}
// encode
OutputStream exiOS = new FileOutputStream(exiLocation);
EXIResult exiResult = new EXIResult(exiFactory);
exiResult.setOutputStream(exiOS);
encode(exiResult.getHandler());
exiOS.close();
// decode
EXISource saxSource = new EXISource(exiFactory);
XMLReader xmlReader = saxSource.getXMLReader();
decode(xmlReader, exiLocation);
}Se la variabile booleana exiCompression risulterà vera, nell'oggetto exiFactor verrà impostata la modalità codifica su COMPRESSION, abilitando la compressione EXI. Di default la modalità di codifica è impostata su BIT_PACKED.
Da notare alcuni aspetti. Nel metodo codeSchemaLess abbiamo definito una grammatica priva di schema (createSchemaLessGrammars). Ciò poteva essere omesso in quanto è l'opzione di default. Scopo della grammatica è quello di definire le regole cui è soggetto il documento XML, regole ad esempio definite tramite XSD.
Il nucleo attorno al quale tutto ruota è l'EXIFactory, classe che racchiude gli elementi della configurazione utili alla codifica e relativa decodifica. Sono informazioni da condividere nel caso in cui le opzioni di codifica/decodifica non siano quelle di default.
Lanciando a scopo di test il main con XML e relativo schema di default e richiedendo la compressione EXI (terzo argomento true) avremo come risultato oggetti (notebook.xml_exi e notebook.xml_exi_schema) che occupano poco più spazio degli stessi oggetti ottenuti con codifica su bit (CodingMode.BIT_PACKED). Il documento originario era già di piccole dimensioni e in questi casi le opzioni di default funzionano meglio.
Se invece il test viene eseguito sul documento SampleGeospatialReference, otterremo oggetti che occupano circa la metà dell'equivalente ottenuto in modalità default, ossia oggetti più piccoli di 10 volte rispetto all'originale nel caso schema-less e di quasi 20 volte più piccoli nel caso schema-informed. Un risultato apprezzabile.
Come detto, è possibile anche settare le FidelityOption, ad esempio per abilitare la modalità Strict:
exiFactory.setFidelityOptions(FidelityOptions.createStrict());EXIficientUtilities: utilizzo tramite script
Abbiamo visto in precedenza che è possibile utilizzare il bundle come archivio eseguibile per mezzo degli scripts annessi. Possiamo sfruttare lo stesso archivio per ospitare il nuovo main che abbiamo realizzato, semplicemente copiando e incollando il compilato della classe appena realizzata nella corrispondente cartella "bin" dell'archivio decompresso (se, come ipotizzato, è stata realizzata nel default package e si lavora con Eclipse privo di tools di building quali maven, potremo trovare la classe compilata nella posizione: "bundle/bin/EXIficientUtilities.class"). Tutto ciò è utile se si è provveduto a creare una copia del bundle nel workspace utilizzato con Eclipse (o equivalente con altro IDE). Se invece si è lavorato direttamente sull'archivio decompresso, vi saranno già disponibili sorgente e compilato della classe EXIficientUtilities.
A questo punto è possibile creare il nuovo script di lancio che va a richiamare il main che abbiamo realizzato modificando quello di partenza; "run-ExiUtilities.bat":
:: EXI Coding
java -cp .;bin;lib/exificient.jar;lib/xercesImpl.jar;lib/xml-apis.jar EXIficientUtilities sample-data/SampleGeospatialReference.xml sample-data/SampleGeospatialReference.xsd true
PAUSErun-ExiUtilities.sh:
#!/bin/bash
java -cp .:bin:lib/exificient.jar:lib/xercesImpl.jar:lib/xml-apis.jar EXIficientUtilities sample-data/SampleGeospatialReference.xml sample-data/SampleGeospatialReference.xsd truePossiamo provare a lanciare lo script d'avvio fornendo in ingresso solo l'XML e questa volta non otterremo errori.
Esecuzione dello script run-ExiUtilities
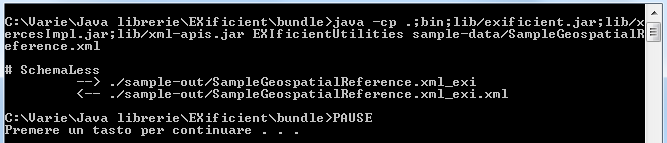
In modo analogo sarà possibile provare lo script fornendo in ingresso anche lo schema, o provando ad abilitare la compressione EXI inserendo true come terzo argomento.
Conclusioni
EXIficient, implementa la specifica EXI, formato binario di scambio degli XML. Abbiamo provato a utilizzare le opzioni della specifica e abbiamo visto che EXIficient ha una buona copertura dello standard, pur non essendo ancora arrivato alla release 1.0. I risultati sono in linea con le valutazioni fatte dal W3C per la specifica.

