
OpenStack è un sistema operativo cloud, modulare, in grado di offrire servizi di gestione di processi e storage secondo il modello IaaS (Infrastructure as a Service).
È un progetto nato nel 2010 da una collaborazione tra NASA e Rackspace Cloud, che deve la sua rapida crescita a contributi provenienti da fronti diversi.
Da un lato vi è la sua natura totalmente open source: OpenStack è scritto in Python ed utilizza diversi altri software
liberi; ciò ha contribuito a garantirgli il supporto di un'ampia comunità. D’altro canto, una spinta determinante al suo sviluppo si deve al forte
interesse di grandi realtà industriali come HP, Cisco, Dell, AT&T e moltissimi altri.
I progressi di OpenStack sono stati scanditi dal susseguirsi di numerose release, una descrizione delle quali è consultabile sulla pagina di Wikipedia. L'ultima versione stabile è denominata Juno.
In questo articolo è presentata una panoramica di questo progetto. Affronteremo pertanto una descrizione dei moduli che lo compongono, della sua
architettura e delle funzionalità, sperimentando queste ultime grazie ad alcune piattaforme di test presenti in rete.
I moduli di OpenStack
L'immagine seguente, tratta dal sito ufficiale del progetto, è particolarmente indicativa delle finalità di OpenStack.

Essa mostra come l'ossatura della piattaforma sia costituita da tre grosse funzionalità – compute
network
storage
tramite browser) o opportune API di programmazione.
I moduli più importanti di Openstack sono:
- Nova (Compute)
comunicazione interna. I suoi compiti vengono espletati attraverso diversi servizi specializzati, coordinati per collaborare. Tra questi spiccano per
importanza nova-schedule nova-compute
installato sulla macchina fisica per gestire le varie fasi di un'istanza, dall'avvio allo spegnimento; - Neutron (Network)
Quantum
partire dalla versione OpenStack Folsom. In precedenza, le sue mansioni venivano svolte da nova-network
limiti, specialmente per configurazioni avanzate. Pertanto il servizio di rete è stato isolato in un modulo a sé stante che si occupa della infrastruttura
di comunicazione in toto - Swift (Object Storage)
di archiviazione molto ampi da dedicare a storage online o backup; - Keystone (Identity)
- Glance (Image Service)
compone di tre parti principali: un database (tipicamente MySQL), un servizio di catalogazione delle immagini virtuali (spesso conservate tramite Swift, ma
ciò non è obbligatorio) e un set nutrito di API per l'interazione; - Horizon (Dashboard)
OpenStack. Tecnicamente potrebbe essere sostituita con un'altra di produzione propria, dal momento che un qualunque progetto web che sfrutti le API di
OpenStack per interagire con la piattaforma può sostituirlo. In effetti, questo tipo di scelta è spesso intrapresa dai fornitori di servizi Cloud, essendo
la dashboard una parte del progetto molto evidente per l'utilizzatore finale; - Cinder (Block Storage)
servizio di Nova, denominato nova-volume
Architettura di OpenStack
L'elenco dei moduli fornito nel paragrafo precedente rende l'idea degli scopi e delle funzionalità delle singole parti costituenti OpenStack, ma ancora non
ci fornisce una visione d'insieme.
L'immagine seguente mostra uno schema architetturale del progetto:
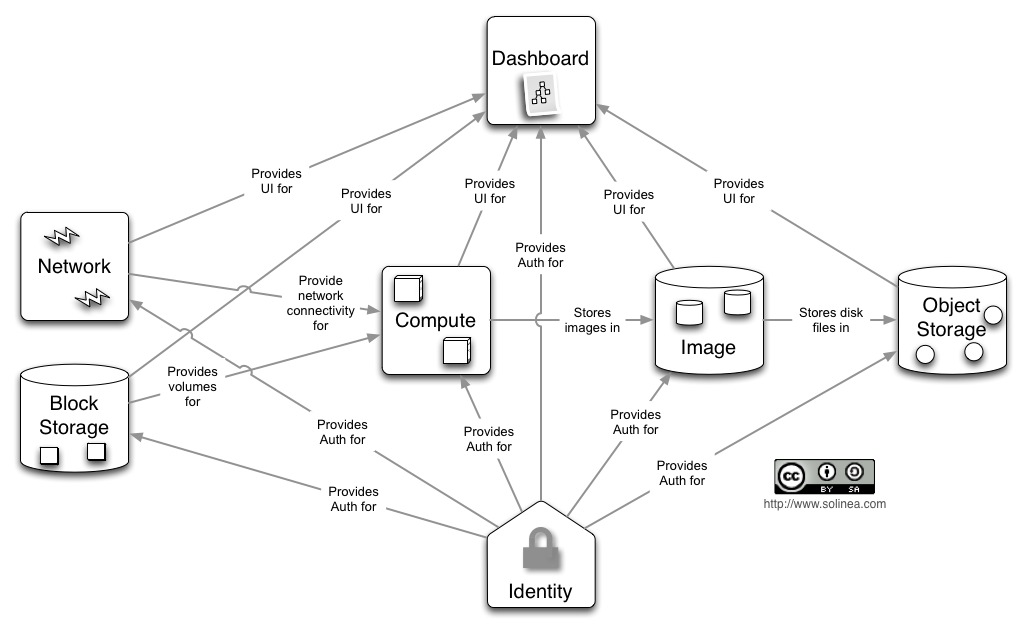
Sebbene possa sembrare uno schema un po’ confusionario, cerchiamo di fare chiarezza ponendo l’attenzione sugli aspetti salienti:
- due moduli sono collegati a tutti gli altri: si tratta della Dashboard
Identity
prima rappresenta l'interfaccia utente, e pertanto scambia dati con tutti gli altri moduli per poterli utilizzare e visualizzare. Il secondo offre
funzionalità di autenticazione e autorizzazione per tutti gli altri componenti dello schema; - la porzione destra del grafo è relativa alla gestione delle immagini virtuali. Tutti i dati relativi sono collocati in Image
sfrutta i servizi di Object Storage - Compute
- Network
“mondo esterno”. Network come Block Storage
L'immagine successiva mostra uno schema architetturale più approfondito.
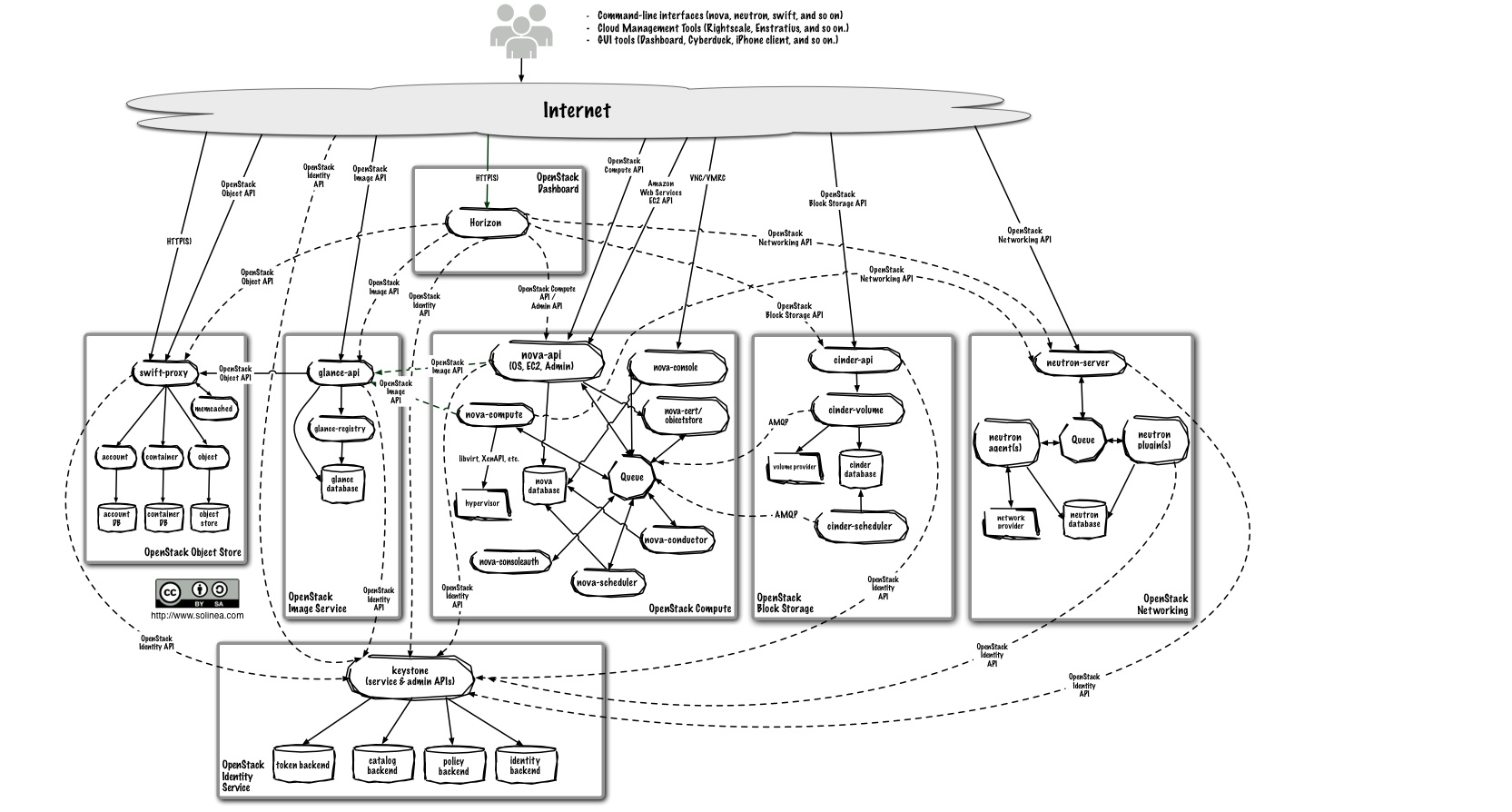
Questo schema ricalca l'organizzazione del precedente, ma è ribaltato orizzontalmente; di conseguenza il servizio di Object Storage (Swift) che nella
precedente immagine è all'estrema destra, adesso si trova dalla parte opposta.
Quest’ultimo schema si rivela interessante perché mostra le sotto-componenti di ogni modulo e le direzioni del dialogo tra esse. Se si vorranno approfondire
meglio le singole porzioni di OpenStack, si potrà utilizzare questa immagine per orientarsi tra le numerose funzionalità di cui questo sistema dispone,
come se fosse una sorta di mappa.
Iniziare con OpenStack
Acquisiti i primi concetti su OpenStack, è il momento di iniziare ad usarlo. L'installazione di un sistema così ampio rischia necessariamente di non essere
troppo agevole. Spesso, nell'esperienza professionale, un'architettura simile non viene sempre approntata da zero, ma spesso vi si accede tramite servizi
offerti da provider.
Per questi motivi e per il grande valore professionale che ha la conoscenza di OpenStack, prima di imbattersi in un'installazione in proprio è il caso di
approfondire l'utilizzo pratico di questo sistema.
Esistono risorse che consentono di iniziare lo studio di OpenStack senza averlo direttamente a disposizione nella sua totalità. Abbiamo a disposizione
almeno due opzioni: utilizzando DevStack, un'installazione di sperimentazione cui si accennerà a breve, o con piattaforme online, già pronte e offerte come esperienza formativa, il cui uso verrà descritto in maggiore dettaglio nel prossimo
paragrafo.
DevStack
(documentato nella documentazione di OpenStack) può essere installato in maniera relativamente
semplice.
L'installazione e la configurazione consistono sommariamente nei seguenti passaggi:
- installazione di una distribuzione Linux
- installazione di git
- download del codice tramite il comando seguente:
[code]git clone https://git.openstack.org/openstack-dev/devstack[/code] - configurazione di alcuni parametri e avvio dello script stack.sh
Si noti che DevStack è uno strumento validissimo per lo studio e la sperimentazione, ma non è una buona soluzione da utilizzare in produzione.
Utilizzare OpenStack
In questo paragrafo utilizzeremo OpenStack sperimentando i concetti fin qui appresi. Lo faremo tramite TryStack, una
piattaforma online già pronta.
Le indicazioni fornite nella homepage spiegano che TryStack è un'opportunità offerta gratuitamente a chi vuole sperimentare OpenStack e anch'essa, come
DevStack, non rappresenta una soluzione per la produzione.
L'accesso alla piattaforma è praticamente immediato, e richiede soltanto di fornire le credenziali del proprio account Facebook.
L'esperimento che stiamo per compiere ci permetterà di creare una macchina virtuale e collegarla in Internet. Lavoreremo al suo interno da
remoto tramite il protocollo SSH e vi installeremo il server web Apache. Le operazioni appena descritte non appaiono
particolarmente innovative, ma saranno tutte svolte all'interno dell'infrastruttura cloud offerta da OpenStack.
Effettuato il login su trystack.org, quella che si apre di fronte a noi è la dashboard, il pannello di amministrazione. Sulla
sinistra è invece situato il menu principale.

Passaggio 1: creazione di una rete interna
Selezioniamo la voce Networks nel menu Network. La finestra di dialogo che appare richiede la configurazione di rete.
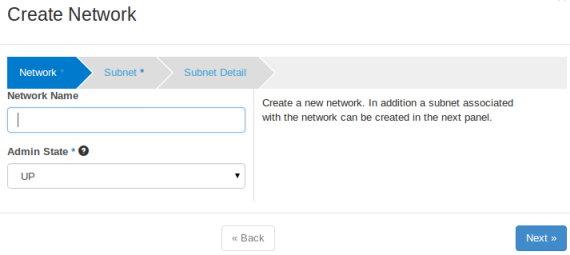
I parametri minimi da inserire sono Network name
Network Address
Subnet
Network Address
192.168.100.0/24
pannello.
Selezionando la voce di menu Network --> Network Topology
mostrato un bus azzurro sulla sinistra che indica la rete esterna (in pratica Internet), mentre quello arancione rappresenta proprio la rete interna che
stiamo componendo. Via via che creeremo elementi, essi verranno tutti collegati a questa; perciò, dopo ogni operazione, sarà utile tornare a controllare la
topologia di rete.

Passaggio 2: creazione di una macchina virtuale
Spostiamoci ora nel menu Compute e, selezionando Instances. Verrà visualizzato l'elenco delle istanze già disponibili. Nel nostro caso,
ovviamente, sarà ancora vuoto.
Cliccando sul pulsante Launch instance (in alto a sinistra) lanceremo una nuova finestra di dialogo per la configurazione della nuova macchina
virtuale.
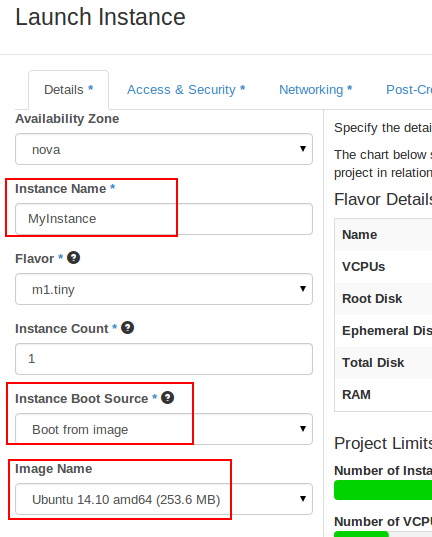
I dati da fornire sono piuttosto intuitivi. In questo caso, creiamo una macchina per Ubuntu 14.10. Forniamo il nome della nuova instance Instance Name Boot from Image Instance Boot Source Image Name
Visto che dovremo fare accesso da remoto con SSH, possiamo predisporre nella pagina Access & Security
chiave pubblica.
Ricordiamo che per produrre una nuova coppia di chiavi, dobbiamo usare il seguente comando nel terminale del nostro sistema operativo:
[code]ssh-keygen -t rsa -f nome_chiave[/code]
Se, ad esempio, come nome della chiave abbiamo scelto openstack.key openstack.key openstack.key.pub
Creata l'istanza, essa sarà già in esecuzione (running
Passaggio 3: creazione di un Router
Per collegare la nostra macchina alla Rete abbiamo bisogno di un router. Tramite menu, selezioniamo Network --> Routers e clicchiamo sul
pulsante Create Router. Per collegarlo alla rete esterna, una volta visibile nel pannello, selezioniamo Set gateway, e nella finestra di
dialogo che si apre impostiamolo come rete external.
Da un lato il router è quindi ora connesso alla rete esterna, dall'altro dobbiamo legarlo a quella interna da noi creata. Per questo clicchiamo sul nome
del router e cerchiamo il pulsante Add interface. Nella finestra che si apre potremo selezionare per il campo Subnet la rete interna da
noi creata.
Osserviamo nuovamente la topologia di Rete (Network --> Network Topology) e vedremo apparire il nostro router e la nostra istanza virtuale con
i collegamenti alle reti interna ed esterna che abbiamo realizzato.
Passaggio 4: assegnare un indirizzo IP pubblico
Rechiamoci nuovamente sul pannello delle istanze (Compute --> Instances) e alla riga corrispondente all'istanza creata, sulla destra, troviamo un menu a tendina di Actions. Una di esse è denominata Associate Floating IP. Nella finestra di dialogo che si apre possiamo selezionare un indirizzo IP pubblico già definito o richiederne uno nuovo con il pulsante etichettato con
il simbolo +, visibile in figura. Una volta scelto quale indirizzo IP associare, clicchiamo sul pulsante Associate IP.
Passaggio 5: accesso alla macchina virtuale
Fatto ciò, con la macchina virtuale avviata, possiamo accedere ad essa tramite SSH. Grazie alla chiave pubblica fornita non avremo neanche bisogno di usare
una password.
Se la nostra chiave si chiama openstack.key, possiamo eseguire il seguente comando:
[code]ssh -i openstack.key ubuntu@indirizzo IP pubblico[/code]
Avremo così accesso immediato alla macchina. Per provarla, possiamo installare un server web Apache con i normali comandi di Ubuntu:
[code]
sudo apt-get update
sudo apt-get install apache2
[/code]
Aprendo il browser ed inserendo l'indirizzo IP pubblico assegnato, vedremo apparire la pagina di benvenuto di Apache, che riporta il classico messaggio “It
works!”. Ciò dimostra che la nostra macchina creata in OpenStack è funzionante e disponibile in Rete.
Quello visto, ovviamente, è solo un primo esperimento; ma TryStack si presta ad ogni tipo di attività.
Conclusioni su OpenStack: installazione completa ed API
L'installazione vera e propria di OpenStack è un procedimento lungo, ben discusso sulla documentazione ufficiale.
Il processo consta di più fasi, tra cui quelle di progettazione dell'architettura su cui vogliamo predisporre OpenStack, preparazione delle macchine con
sistema operativo installato e studio degli strumenti da utilizzare. Quando tutto sarà pronto si potrà procedere all'installazione dei singoli moduli,
previo soddisfacimento dei prerequisiti. Si consideri comunque che buona parte dei moduli OpenStack sono disponibili come pacchetti precompilati nei
repository delle maggiori distribuzioni Linux.
Altro aspetto di valore di questo progetto è il grande numero di API disponibili, sfruttabili tramite riga di comando o invocazioni REST.
Anch'esse possono essere sperimentate mediante TryStack.
