
È possibile utilizzare il linguaggio di programmazione Python per l'interazione con diverse tipologie di database, sia di tipo SQL che NoSQL. Nel caso di questi ultimi, una delle soluzioni più diffuse è MongoDB, un DBMS non relazionale e document-oriented che archivia i dati tramite una struttura simile a quella utilizzata in JSON e semplifica l'interscambio delle informazioni gestite.
Preparazione e test dell'ambiente di sviluppo
Python non supporta nativamente MongoDB ma necessita dell'installazione di un driver dedicato, nel caso degli esempi che verranno proposti in questo approfondimento è stata scelta la libreria PyMongo che può essere facilmente integrata nel proprio ambiente di sviluppo tramite il package manager pip (Python Package Index), per quanto riguarda invece l'installazione di Python e di MongoDB, comunque particolarmente semplici, si rimanda alle guide dedicate su HTML.it.
Per installare PyMongo, apriamo quindi il prompt dei comandi di Windows o il terminale della distribuzione Linux utilizzata e lanciamo il comando:
python -m pip install pymongo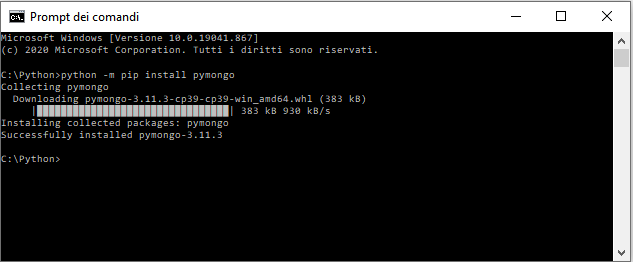
Come qualsiasi altro modulo per Python anche PyMongo può essere richiamato per importazione tramite la keyword import, quindi per verificarne l'installazione è sufficiente salvare la seguente istruzione in un file .py ed eseguirla:
# Importazione del modulo di PyMongo
import pymongoNel caso in cui il driver dovesse essere stato installato correttamente l'esecuzione non produrrà alcun output, più interessante potrebbe essere quindi un test effettuato sulla verifica dei database già presenti di default nel DBMS, operazione che può essere effettuata tramite un'istruzione come la seguente:
import pymongo
# Connessione a MongoDB
connessione = pymongo.MongoClient("mongodb://localhost:27017/")
# Stampa a video della lista dei database
print(connessione.list_database_names())ottenendo un risultato come quello proposto dall'immagine proposta di seguito:

Il codice mostrato in precedenza non fa altro che avviare una connessione tra applicazione e MongoDB, che come è semplice notare avviene specificando l'URL dell'host (in questo caso localhost) completo di porta di ascolto per le chiamate al Database Manager (27017), a cui segue l'uso del metodo list_database_names() che, appunto, mostra una lista dei database disponibili per l'installazione corrente.
La connessione all'engine MongoDB deve essere eseguita prima di qualsiasi interazione tramite il metodo MongoClient() di PyMongo.
Creazione di database e collection
Se si è abituati a lavorare con i database relazionali alcune dinamiche di MongoDB potrebbero sembrare controintuitive, ad esempio con esso perché una base di dati "esista" non è sufficiente che venga "creata", deve essere anche popolata. Nello stesso modo una collection, che è il corrispondente delle tabelle dei database SQL, deve contenere dei record (ma nel caso specifico si parla più precisamente di documenti) perché venga effettivamente generata.
La procedura per la creazione di un database richiede innanzitutto la connessione al DBMS e in secondo luogo l'indicazione del nome che deve essere associato al database stesso:
import pymongo
connessione = pymongo.MongoClient("mongodb://localhost:27017/")
# Creazione del database
nuovodatabase = connessione["griffin"]Una volta eseguita questa istruzione il DBMS rimane in attesa della creazione di una prima collection che può essere effettuata tramite l'oggetto del database (nel nostro caso nuovodatabase
import pymongo
connessione = pymongo.MongoClient("mongodb://localhost:27017/")
nuovodatabase = connessione["griffin"]
# Creazione della collection
nuovacollection = nuovodatabase["personaggi"]A questo punto il prossimo passaggio, necessario per fare in modo che database e collection diventino permanenti, sarà quello relativo all'inserimento dei documenti. Se invece si desidera cancellare una collection esistente, dato nuovacollection
nuovacollection.drop()Inserimento dei documenti
In Python è possibile inserire dei documenti all'interno della collection di un database MongoDB tramite dei dizionari composti da coppie formate da nomi e valori, dove i primi sono i nomi dei campi e i secondi i valori associati a questi ultimi. Il metodo di PyMongo a cui passare un singolo dizionario come parametro è insert_one(), da associare all'oggetto della collection (nuovacollection nell'esempio):
import pymongo
connessione = pymongo.MongoClient("mongodb://localhost:27017/")
nuovodatabase = connessione["griffin"]
nuovacollection = nuovodatabase["personaggi"]
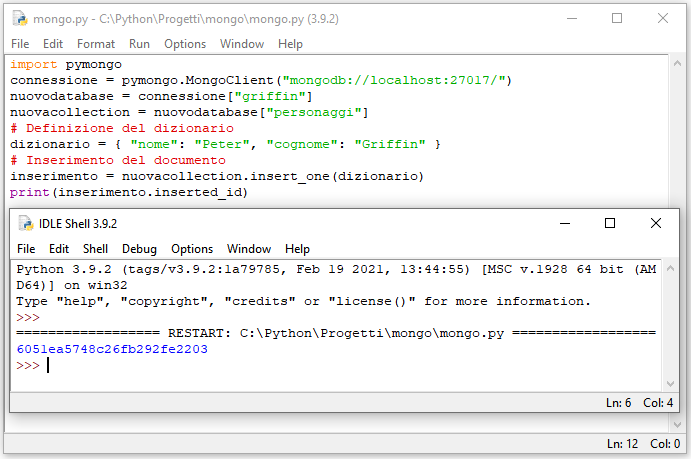
# Definizione del dizionario
dizionario = { "nome": "Peter", "cognome": "Griffin" }
# Inserimento del documento
inserimento = nuovacollection.insert_one(dizionario)
print(inserimento.inserted_id)Si noti l'utilizzo del metodo inserted_id, associato all'oggetto InsertOneResult prodotto dall'inserimento del documento, che consente di accedere all'ID (identificatore univoco) generato automaticamente dal DBMS in seguito all'azione di insert_one().
Se invece si desidera inserire più documenti alla volta il metodo di riferimento è insert_many() a cui passare come argomenti una lista composta da dizionari, come nell'esempio seguente:
import pymongo
connessione = pymongo.MongoClient("mongodb://localhost:27017/")
nuovodatabase = connessione["griffin"]
nuovacollection = nuovodatabase["personaggi"]
# Definizione della lista
lista = [
{ "nome": "Lois", "cognome": "Griffin" },
{ "nome": "Stewie", "cognome": "Griffin" },
{ "nome": "Meg", "cognome": "Griffin" },
{ "nome": "Chris", "cognome": "Griffin" },
{ "nome": "Brian", "cognome": "Griffin" }
]
# Inserimento dei documenti
inserimento = nuovacollection.insert_many(lista)
print(inserimento.inserted_ids)Anche in questo caso gli ID verranno assegnati automaticamente ma in alternativa è comunque possibile personalizzarne il valore. Per fare ciò quest'ultimo deve essere esplicitato al momento della definizione della lista tramite il campo _id:
# Definizione della lista
lista = [
{ "_id": 1, "nome": "Peter", "cognome": "Griffin" },
{ "_id": 2, "nome": "Lois", "cognome": "Griffin" },
{ "_id": 3, "nome": "Stewie", "cognome": "Griffin" },
{ "_id": 4, "nome": "Meg", "cognome": "Griffin" },
{ "_id": 5, "nome": "Chris", "cognome": "Griffin" },
{ "_id": 6, "nome": "Brian", "cognome": "Griffin" }
]In ogni caso _id dovrà presentare un valore univoco per cui non verranno accettati ID duplicati.
Estrazione dei dati da una collection
Una volta inseriti dei dati in una collection è possibile estrarli attraverso dei metodi specifici di PyMongo: find_one(), che seleziona soltanto il primo documento registrato, e find(), che se utilizzato senza argomenti restituisce tutti i documenti di una collection come accadrebbe con SELECT * FROM nel caso dei database SQL.
Interrogando la collection precedentemente creata con find_one() avremo quindi:

Mentre con find() i documenti estratti dovranno essere sottoposti ad un ciclo (for nel codice proposto come esempio) per poter essere visualizzati:
import pymongo
connessione = pymongo.MongoClient("mongodb://localhost:27017/")
nuovodatabase = connessione["griffin"]
nuovacollection = nuovodatabase["personaggi"]
# Estrazione dei documenti di una collection
for selezione in nuovacollection.find():
print(selezione)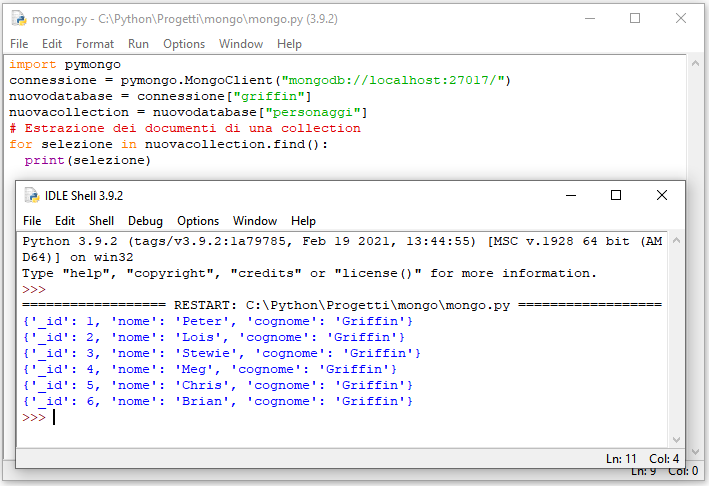
Per limitare il numero di risultati estratti è possibile utilizzare il metodo limit() a cui passare come parametro un valore intero, volendo selezionare soltanto i primi 3 documenti della nostra collection utilizzeremo quindi il metodo in questo modo:
# Limitare i risultati da estrarre
selezione = nuovacollection.find().limit(3)
for i in selezione:
print(i)Interrogazioni più raffinate possono essere effettuate specificando il valore da estrarre, esattamente come accadrebbe utilizzando la clausola WHERE di SQL. Il codice seguente consente per esempio di estrarre soltanto il documento in cui il campo nome è valorizzato come Brian:
# Estrarre risultati specifici
criterio = { "nome": "Brian" }
selezione = mycol.find(criterio)
for i in selezione:
print(i)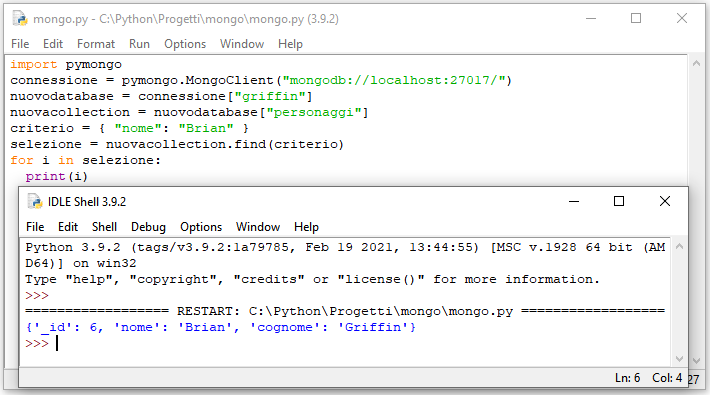
Dato che non sempre si ha l'esigenza di estrarre i valori di tutti campi è possibile infine escludere quello non desiderato tramite l'argomento 0:
# Escludere un campo dall'estrazione
for i in nuovacollection.find({},{ "cognome": 0 }).sort("nome", -1):
print(i)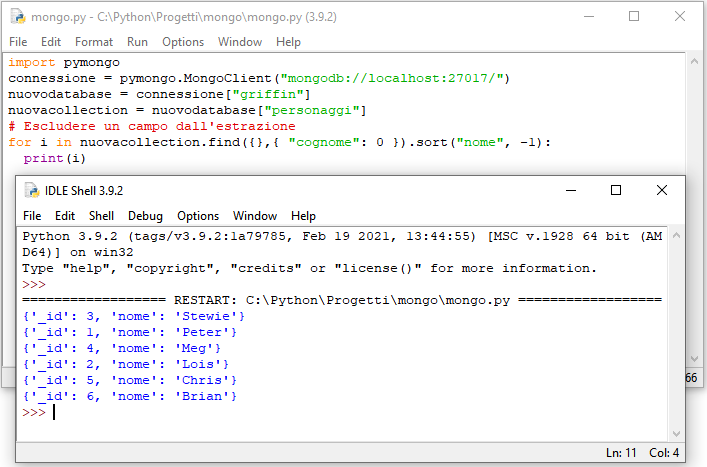
Si noti la presenza del metodo sort() nel codice, quest'ultimo permette di ordinare i valori estratti in base ad un criterio (nello specifico il valore del campo nome), quando valorizzato su -1 esso determina un ordinamento discendente, su 1 l'ordinamento è invece ascendente.
Aggiornamento e cancellazione dei dati
Per aggiornare un singolo documento è possibile utilizzare il metodo update_one() che accetta due parametri: il documento da modificare e il nuovo valore da impostare. Nell'esempio seguente il documento in cui il campo nome è valorizzato come Brian (con _id pari a 1) vedrà quest'ultimo sostituito da Homer:
# Escludere un campo dall'estrazione
criterio = { "_id": 1 }
valore = { "$set": { "nome": "Homer" } }
nuovacollection.update_one(criterio, valore)
# Stampa del documento aggiornato:
criterio_estrazione = { "_id": 1 }
for i in nuovacollection.find(criterio_estrazione):
print(i)update_one() agisce soltanto sulla prima corrispondenza individuata, nel caso in cui si vogliano invece modificare più dati che corrispondono ad un determinato valore il metodo da utilizzare è update_many().
Quando infine si vuole cancellare il primo documento che corrisponde ad un criterio specifico il metodo disponibile è delete_one() da utilizzare in questo modo:
# Rimuovere dati da una collection
criterio = { "nome": "Lois" }
nuovacollection.delete_one(criterio)
for i in nuovacollection.find():
print(i)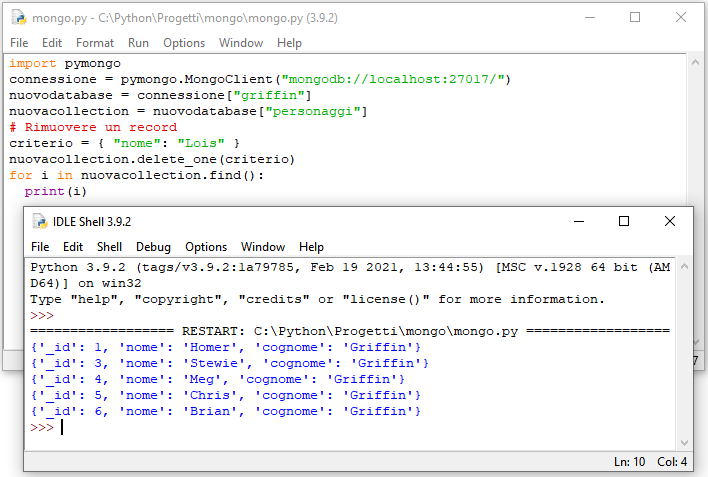
Se invece si vogliono rimuovere più documenti che corrispondono ad un determinato criterio, il metodo a disposizione è delete_many().
