
Prima di spiegare "cosa è NHibernate" è a mio avviso più interessante spiegare cosa non è, in modo da evitare possibili confusioni. NHibernate non è una libreria da usare per evitare la scrittura di codice SQL per accedere ad un database; se avete infatti una struttura già pronta e pensate di scrivere una classe per ogni tabella per gestire l'accesso ai dati, allora tanto vale utilizzare il Dataset Strongly Typed di ADO.NET, che ha indubbiamente il vantaggio di essere maggiormente integrato nel sistema di sviluppo.
Cos'è un ORM
NHibernate è un ORM, acronimo che sta per Object Relational Mapper, ovvero una libreria in grado di mappare oggetti su Database Relazionali e viceversa. In pratica un ORM implementa il pattern Data Mapper [POEAA-DM] ed è in grado di gestire la persistenza di oggetti, termine che indica genericamente l'operazione di salvataggio dello stato dell'oggetto su un supporto stabile.
La necessità di un ORM nasce dall'intrinseca differenza tra il modello relazionale è quello ad oggetti; quest'ultimo infatti ha concetti come ereditarietà, polimorfismo, relazioni bidirezionali ed altre che non hanno una controparte nel mondo relazionale dei database. Per questa ragione, se si ha la necessità di gestire la persistenza su database relazionali, è consigliabile appoggiarsi ad una libreria che si occupi di gestire nella maniera più trasparente possibile le trasformazioni necessarie tra questi due mondi.
Gli ORM in generale sono indispensabili quando l'architettura della propria applicazione è fortemente basata sul Domain Model [POEAA-DDD] [DDD] e quindi si modella la logica di business con tutti i paradigmi dell'Object Orientation. Questo processo è il più adatto per un ORM, si parte infatti dal modello ad oggetti ed in base ad esso si crea una struttura di Database dedicata per gestirne la persistenza. Il processo inverso, partire da uno schema di database preesistente e da questo arrivare al modello ad oggetti è meno ideale, ma anche in questo caso un ORM mostra la sua potenza, dato che permette di evitare la dicotomia un oggetto una tabella, che chiaramente finisce per creare un insieme di oggetti strutturati secondo il modello relazionale, andando cosi a perdere la flessibilità di una struttura pienamente OO. Vediamo ora un primo semplice esempio che permetterà di familiarizzare con NHibernate.
Il primo progetto
Il progetto minimale NHibernate deve referenziare quattro assembly principali: il NHibernate.dll la Iesi.Collections il Log4Net e il Castle.DynamicProxy.
La prima operazione da fare è scrivere i file di mapping, in formato XML, che costituiscono il cuore del nostro dominio, perché indicano a NHibernate come mappare i vari oggetti nelle tabelle del database.
È anche possibile decorare gli oggetti con attributi specifici di NHibernate, invece di usare file XML esterni, ma questo secondo approccio è meno adottato per il principio di persistence ignorance, ovvero "gli oggetti non debbono contenere nulla correlato alla persistenza".
Per il primo esempio si parte con una classe veramente minimale, in modo da acquisire le conoscenze di base su cui poggiare gli esempi successivi. Esaminiamo lo schema della classe ed a fianco il file di mapping relativo.
(Click per ingrandire)

Nota
NHibernate-mapping.xsd
NHibernate-configuration.xsd
XMLSchema
.hbm.xml
Analizzando il mapping mostrato in Figura 2 si può vedere come nel tag radice viene indicato l'assembly (NHSample
NHSample.Entities
<class>
table
lazy=false
A questo punto è necessario specificare uno ad uno tutti i campi o proprietà della classe che si vuole salvare nel DB. NHibernate analizza la classe tramite reflection ed è quindi in grado di accedere anche ai campi privati, questa caratteristica, che ad un primo esame sembra violare il principio di incapsulamento, è invece veramente utile, ad esempio per il campo id. Quest'ultimo infatti è molto particolare e lo si vede anche dal fatto che nel mapping viene identificato come id, ad indicare che è il campo dell'oggetto che ne defisce l'identità. Nel mapping viene poi indicato che il membro mappato è un campo e non una proprietà (access="Field"
access="property"
unsaved-value="0"
insert
update
Nell'elemento <id>
Per le altre proprietà il mapping è molto più semplice dato che basta specificare il nome della proprietà stessa, la colonna sul database da utilizzare (che può essere omesso se ha lo stesso nome della proprietà) ed infine il tipo che, sebbene possa essere omesso, è sempre buona norma indicare.
I file di configurazione
Esistono vari modi per configurare NHibernate, il più comune è inserire nel file di configurazione principale del progetto (web.config o app.config) una sezione apposita.
Listato 1. Configurazione di NHibernate
<configSections>
<section name="NHibernate" type="System.Configuration.NameValueSectionHandler, System, Version=1.0.5000.0,Culture=neutral, PublicKeyToken=b77a5c561934e089" />
</configSections>
<!--Sql server connection-->
<NHibernate>
<add key="hibernate.connection.driver_class"
value="NHibernate.Driver.SqlClientDriver" />
<add key="hibernate.dialect"
value="NHibernate.Dialect.MsSql2005Dialect" />
<add key="hibernate.connection.provider"
value="NHibernate.Connection.DriverConnectionProvider" />
<add key="hibernate.connection.connection_string"
value="Server=localhostsql2005; Integrated Security=SSPI; Database=NHSample;" />
<add key="hibernate.show_sql"
</NHibernate>
Le informazioni minime che si debbono fornire sono: il driver fisico da utilizzare per accedere al DB (SqlClientDriver), il dialetto (che specifica il tipo esatto di database usato Es. MsSql2005Dialect), il provider (DriverConnectionProvider) ed infine la stringa di connessione.
Come valore aggiuntivo è stato inserito show_sql che permette di visualizzare nella console tutto il codice SQL server che viene inviato al database. Questa funzionalità è particolarmente utile perché permette di visualizzare esattamente le operazioni che vengono fatte sul DB.
L'impostazione base è mostrare il codice SQL nella console, destinazione piuttosto inutile se si sta facendo una applicazione Web. Dato che internamente NHibernate utilizza log4net con un logger di nome NHibernate.SQL, è molto semplice configurare log4net per avere le informazioni su file.
Listato 2. Esempio di configurazione di log4net
<log4net>
<appender name="OutputSQL" type="log4net.Appender.FileAppender">
<param name="File" value="OutputSql.txt" />
<param name="AppendToFile" value="false" />
<layout type="log4net.Layout.PatternLayout">
<param name="ConversionPattern" value="%m;" />
</layout>
</appender>
<logger name="NHibernate.SQL" additivity="false">
<level value="DEBUG" />
<appender-ref ref="OutputSQL" />
</logger>
</log4net>
Grazie a questa semplice configurazione al termine dell'esecuzione tutto il codice SQL generato si troverà nel file OutputSQL.
SessionManager
L'oggetto principale con cui ci si interfaccia a NHibernate è l'oggetto sessione, restituito tramite l'interfaccia ISession. Data la centralità e l'importanza della sessione, nel progetto si crea solitamente un SessionManager, ovvero un oggetto in grado di centralizzarne la gestione.
Il SessionManager si occupa di gestire la creazione delle sessioni , il cui costruttore statico non fa altro che inizializzare un'oggetto chiamato SessionFactory.
Listato 3. Costruttore del SessionManager
Configuration cfg = new Configuration();
cfg.AddAssembly(Assembly.GetExecutingAssembly());
factory = cfg.BuildSessionFactory();
Per caricare la configurazione basta creare un oggetto di tipo NHibernate.Cfg.Configuration, e poi si procede semplicemente aggiungendo gli assembly che contengono i file di mapping. Se si commettono errori nei mapping, la classe SessionManager genererà un'eccezione nella chiamata al metodo Configuration.AddAssembly, è in questo punto infatti che NHibernate esamina le risorse dell'assembly, individua i mapping e li analizza per creare dinamicamente le classi che gestiranno la persistenza. I messaggi di errore sono sempre molto dettagliati e non si deve dimenticare di controllare a cascata la proprietà InnerException fino a trovare la vera spiegazione dell'errore.
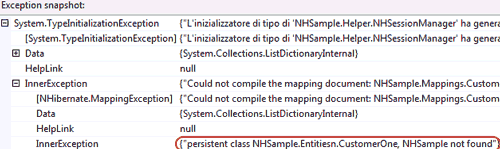
In questo caso infatti bisogna scendere di ben due livelli, ma il messaggio è quantomai chiaro, l'entità è stata specificata come NHSampleEntitiesn.CustomerOne, è stato quindi sbagliato il nome della classe.
Per iniziare
Il primo test è un semplicissimo inserimento, il codice è veramente banale, è contenuto nel file Program.cs ed il metodo è chiamato ExampleInsert().
Listato 4. Esempio di inserimento
private static void ExampleInsert() {
CustomerOne customer = new CustomerOne("Gian Maria", "Ricci");
using (ISession session = NHSessionManager.GetSession() ) {
session.SaveOrUpdate(customer);
session.Flush();
}
}
Il primo fatto importante da notare è che l'oggetto ISession di NHibernate è incluso in un blocco using, questo è fondamentale perché la sessione utilizza al suo interno oggetti come Connessioni e Transazioni, per cui è necessario che tali risorse vengano rilasciate correttamente quando si termina di utilizzare la sessione stessa, pena un possibile connection leak. Dimenticare di chiamare il Dispose() significa infatti delegare il rilascio delle risorse al garbage collector e quindi in un tempo indefinito nel futuro.
Il secondo fatto importante è che è stato chiamato il metodo SaveOrUpdate() che internamente capisce se l'oggetto deve essere salvato o aggiornato. Questa decisione viene infatti presa in base al valore della chiave primaria, che nel caso di oggetti nuovi è pari a zero (ricordare l'attributo unsaved-value), mentre nel caso di oggetti già salvati è pari al valore di identità restituito dal database. Infine, grazie all'impostazione show_sql è possibile vedere nella console il codice SQL che NHibernate ha generato per inserire l'oggetto.

L'id dell'oggetto è stato recuperato grazie alla select SCOPE_IDENTITY() di SQL Server. L'ultima nota riguarda la chiamata al metodo ISession.Flush() che è necessario invocare per informare la sessione che vogliamo propagare al database tutti gli eventuali cambiamenti degli oggetti. Questa funzionalità verrà spiegata meglio in un articolo successivo, per ora basti pensare che la sessione si comporta come uno stream, ovvero non propaga immediatamente al database i cambiamenti degli oggetti, ma solo quando lo reputa necessario. Chiudere o chiamare il Dispose() su una sessione, senza chiamare il Flush(), non propaga al DB tutte i nostri cambiamenti, per cui si deve fare molta attenzione.
Cambiare Database
Una delle particolarità più interessanti degli ORM è che essi sono in grado di accedere a database differenti in maniera praticamente trasparente. Dato che le query SQL e gli oggetti di accesso al database sono creati dinamicamente dalla libreria e soprattutto visto che il dominio degli oggetti segue la persistence ignorance, è spesso possibile cambiare tipologia di database con sforzo veramente minimo. Se volessimo modificare l'esempio precedente per accedere ad un database Access, la prima operazione da fare è creare un database con lo stesso schema utilizzato in SQL, naturalmente con le differenze del caso.

Access non ha infatti la proprietà identity per le colonne, ma simula con la colonna contatore, a questo punto bisogna cambiare il file di configurazione in questo modo.
Listato 5. Configurazione per DB Access
<NHibernate>
<add key="hibernate.connection.driver_class"
value="NHibernate.JetDriver.JetDriver, NHibernate.JetDriver" />
<add key="hibernate.dialect"
value="NHibernate.JetDriver.JetDialect, NHibernate.JetDriver" />
<add key="hibernate.connection.provider"
value="NHibernate.Connection.DriverConnectionProvider" />
<add key="hibernate.connection.connection_string"
value="Provider=Microsoft.Jet.OLEDB.4.0;Data Source=DatabasesNHSample.mDB" />
<add key="hibernate.show_sql" value="true" />
</NHibernate>
Naturalmente è anche necessario mettere un riferimento alla dll NHibernate.JetDriver.dll che contiene i driver per accedere ad Access.
Quindi è sufficiente cambiare la classe dei driver, il dialetto e naturalmente la stringa di connessione, ma la cosa più importante è che non bisogna ricompilare nulla, ma solamente cambiare il file di configurazione. Se si esegue nuovamente il programma si può verificare con piacere che funziona tutto correttamente e nella console si può osservare il codice SQL generato, che naturalmente è diverso dal precedente.

Come in ogni query Access i parametri sono passati posizionalmente dato che access non supporta parametri con nome, e la selezione dell'identità è fatta con una seconda query: select @@identity. A questo punto è interessante prendere in esame anche una connessione con oracle, perché in questo caso è necessario invece andare a cambiare il mapping.
Se si imposta la connessione Oracle nel file di configurazione e si lancia il programma viene generata una eccezione di sequenza non trovata, e nella console troviamo il seguente SQL generato da NHbernate "SELECT hibernate_sequence.nextval FROM xxx". La nostra classe infatti ha come generatore di id la classe native vista in precedenza e in Oracle la gestione nativa degli id è data dalle sequence. Con Oracle quindi NHibernate cerca una sequenza particolare chiamata hibernate_sequence e naturalmente è sufficiente crearla perché tutto funzioni nuovamente in modo corretto. L'approccio di usare una sola sequence per tutti gli oggetti potrebbe anche essere interessante, ma chi preferisce usare per ogni tabella una sequence specifica deve alterare invece il file di mapping.
Listato 6. Utilizzare una sequenza speciale su Oracle
<id name="Id" column="alin_id" type="int" unsaved-value="0">
<generator class="native">
<param name="sequence">sq_am_alertinstance</param>
</generator>
</id>
In pratica si è semplicemente aggiunto un parametro al generatore nativo che indica il nome della sequenza da utilizzare. A questo punto si può eseguire nuovamente il programma con un breakpoint sull'istruzione Session.Flush(). L'oggetto, dopo la chiamata al metodo SaveOrUpdate(), ha un id valido e diverso da zero, ma se controllate la tabella Oracle ancora non è stato inserito nulla. NHibernate ha infatti effettuato solamente un SELECT dalla sequence (operazione visibile dalla console) per conoscere l'id da assegnare all'oggetto, ma ha deciso di non salvare l'oggetto per ora. Naturalmente quando viene eseguita l'istruzione Session.Flush() NHibernate propagherà al DB tutte le operazioni pendenti ed inserirà fisicamente l'oggetto.


