
Il modello architetturale REST sembrerebbe essere ormai consolidato ed avrebbe soppiantato i vecchi Web Service basati su SOAP che spopolavano verso la fine degli anni novanta e gli inizi del 2000. Quasi ogni servizio online moderno mette a disposizione le proprie API REST per poter essere gestito programmaticamente: da Twitter a Facebook, da Google ad Azure, per citare solo alcuni dei servizi più noti. Ma anche gli sviluppatori di aziende meno blasonate hanno sviluppato API REST per predisporre l’integrazione con altre applicazioni e servizi. In poche parole, a quasi vent’anni dalla dissertazione di Roy Thomas Fielding sull’architettura REST, potremmo affermare che essa è ormai una tecnologia acquisita.
Ma siamo proprio sicuri di questo? Siamo sicuri che gli sviluppatori abbiano veramente compreso cosa ha proposto Fielding ed abbiano veramente seguito le linee guida per costruire sistemi ad architettura REST, noti anche come sistemi o applicazioni RESTful?
Queste domande potrebbero sembrare peregrine, ma in realtà non lo sono, come proveremo a mostrare in questo articolo.
La tua API è RESTful?
Se proviamo a chiedere ad un grande numero di sviluppatori una definizione di REST e delle caratteristiche di un’API REST, la maggioranza di essi risponderà con qualcosa di simile alla seguente affermazione:
un’API REST è un’interfaccia di programmazione che usa HTTP per gestire dati remoti
In altre parole, per la maggior parte degli sviluppatori la progettazione di una API RESTful consiste in:
- definire delle risorse (dati) accessibili via Web, ed identificarle con degli URL
- mappare le operazioni CRUD
POSTGETPUTDELETE
Probabilmente qualcuno potrebbe aggiungere che è possibile gestire la content negotiation, cioè la possibilità per il client di chiedere al server una rappresentazione in uno specifico formato invece del classico JSON che diamo per scontato. Ma pochi andrebbero oltre.
Segno del fatto che, parafrasando Douglas Crockford, REST è uno dei modelli architetturali più fraintesi al mondo.
Cos’è veramente REST?
L'acronimo REST sta per REpresentational State Transfer, cioè trasferimento della rappresentazione dello stato. Chi vede un’attinenza tra questo nome e le API comunemente implementate mappando le operazioni CRUD sui verbi HTTP? Probabilmente nessuno. Proprio perché non c’è sostanzialmente alcuna attinenza.
Se andiamo a dare un’occhiata alla dissertazione di Fielding, scopriremo che il suo modello architetturale si basa su sei principi a cui un sistema deve fare riferimento per poter essere definito REST.
In realtà, tali principi sono pressoché comuni alla maggior parte dei sistemi distribuiti. Il principio che caratterizza in particolar modo un sistema REST è quello dell’interfaccia uniforme (Uniform Interface), cioè quello che sostiene che le modalità di interazione tra i componenti del sistema deve essere regolata da convenzioni uniformi. Infatti, Fielding indica quattro vincoli che devono essere rispettati per soddisfare questo principio:
- identificazione delle risorse
- manipolazione delle risorse tramite una loro rappresentazione
- messaggi autodescrittivi
- hypermedia come il motore per la gestione dello stato dell’applicazione
Finalmente l’ultimo vincolo parla dello stato citato all’interno dell’acronimo REST.
Concettualmente, esso focalizza l’attenzione sui collegamenti ipermediali come meccanismo di base per far passare un’applicazione da uno stato all’altro. E come gli altri vincoli, anche questo deve essere rispettato affinché un sistema possa essere definito REST.
Al di là del nome che può incutere un po’ di timore (Hypermedia As The Engine Of Application State), il concetto è abbastanza semplice: un client chiede una risorsa al server (anzi, una sua rappresentazione) ed il server restituisce la risorsa con i collegamenti ad altre risorse correlate, come nel seguente esempio:
{
"id": 463219,
"firstName": "John",
"lastName": "Smith",
"company": "Acme Inc.",
"salary": 72500,
"links": [
{
"href": "https://api.myapp.com/employees/employee/463219",
"rel": "self"
},
{
"href": "https://api.myapp.com/companies/company/375",
"rel": "company"
},
{
"href": "https://api.myapp.com/payments/employee/463219",
"rel": "payments"
}
]
}Il client può seguire il collegamento ad una delle risorse correlate richiedendola al server, il quale la fornirà insieme ai collegamenti di altre risorse correlate. In questo modo il client passa da una risorsa all’altra tramite i reciproci collegamenti, "scoprendo" man mano la presenza di nuove risorse. Questa scoperta dinamica è fondamentale: non si tratta di indirizzi che il client conosce sin dall’inizio, come avviene nei client cosiddetti RESTful implementati dalla maggior parte degli sviluppatori, ma di indirizzi che vengono recepiti man mano che si accede alle risorse messe a disposizione dal server.
Vi ricorda qualcosa questa modalità di interazione tra il client ed il server? Se ci fate caso, questa non è altro che la navigazione di un browser tra le pagine Web.
Infatti, un vero client REST non dovrebbe essere altro che una sorta di browser evoluto che naviga tra le risorse messe a disposizione da un server (o da più server) grazie ai collegamenti tra una risorsa e l’altra. E come avviene per un browser che naviga su un sito Web, l’unico indirizzo di cui un client REST dovrebbe essere a conoscenza è l’entry point delle API. Gli indirizzi delle altre API dovrebbero essere scoperti man mano che le risorse vengono caricate. In altre parole, in un sistema che implementa i principi REST il server avrebbe un ruolo predominante nello stabilire il comportamento del client, il quale si limiterebbe ad interpretare la rappresentazione delle risorse ed a seguire i percorsi ammessi dai collegamenti tra una risorsa e l’altra. Questo ruolo predominante del server avrebbe anche il vantaggio di consentire la variazione della struttura di una risorsa o dei collegamenti tra le risorse senza preavviso, eliminando del tutto la necessità di un versionamento delle API.
Alla luce di tutto questo, volete ancora sostenere che le nostre API siano veramente RESTful?
Il Maturity Model di Richardson
Ricapitolando, fin qui abbiamo provato a dimostrare, definizione alla mano, che la maggior parte delle API spacciate per RESTful in realtà non lo sono affatto. Infatti, la definizione di REST prevede che tutti i vincoli riguardanti la definizione di un’interfaccia uniforme devono essere soddisfatti.
Alcuni sostengono che si potrebbe parlare di diversi livelli di maturità delle API REST citando un noto articolo di Martin Fowler. L’articolo descrive quattro livelli di maturità elaborate da Leonard Richardson per trasformare una semplice chiamata HTTP in una API REST. Il modello può essere rappresentato dalla seguente figura tratta dall’articolo citato:
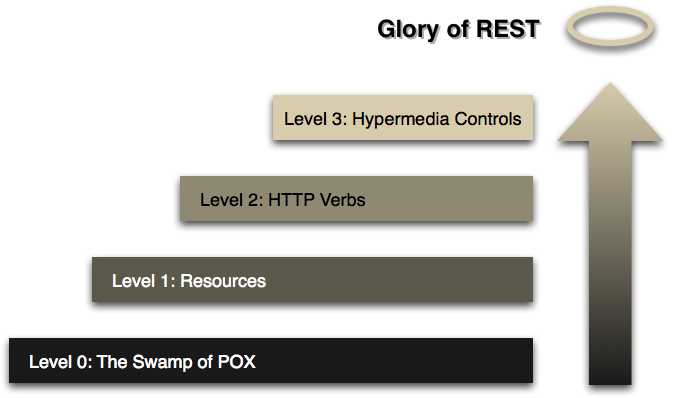
In pratica, partendo dal livello 0 (quello relativo ad una chiamata HTTP verso un URL) possiamo passare ai livelli successivi lavorando sulla rappresentazione delle risorse (livello 1), sulla mappatura tra verbi HTTP e operazioni CRUD (livello 2) ed infine sulla correlazione tra le risorse (livello 3).
Chi fa riferimento a questo modello in genere sostiene che le API comunemente implementate sono sempre API REST, ma di livello 2. In realtà questo è un travisamento sia della definizione di REST sia del modello di Richardson.
Come dice lo stesso Fowler nel suo articolo
Non chiamiamole API REST
In conclusione, è ragionevole affermare che la maggior parte delle API che implementiamo non rispetta tutti i vincoli previsti dall’architettura REST, e pertanto non possiamo definirle RESTful.
Naturalmente non c’è nulla di male nelle API che implementiamo. Esse seguono un modello parzialmente ispirato alle linee guida di REST: non pongono l’accento sulle transizioni di stato delle nostre applicazioni, ma sulla semplice gestione di risorse remote.
Alla luce di quanto discusso, quindi, stiamo attribuendo alle nostre API una qualifica inappropriata: possiamo chiamarle Web API o API HTTP, ma per cortesia non chiamiamole API REST.
