
Amazon offre ormai da anni servizi di cloud computing per le aziende, per gli sviluppatori e in genere per chi abbia bisogno di risorse potenzialmente illimitate on-demand e dalla tariffazione a consumo, ossia dei due punti chiave di un prodotto cloud.
I servizi sono distribuiti sulle tre macro-aree del cloud moderno: servizi di IaaS, ovvero l’erogazione di risorse virtuali la cui governance resta però all’utilizzatore/cliente; servizi di PaaS, ovvero la fornitura di piattaforme applicative utili alla distribuzione di applicazioni, ove la governance è quasi interamente a carico del vendor (in questo caso Amazon); servizi SaaS, ovvero stack applicativi completi ad uso e consumo delle aziende e/o degli stessi sviluppatori, quale compendio dei servizi IaaS e PaaS, ove la governance è interamente a carico del vendor e dove è nascosto ogni dettaglio implementativo.
In questo contesto Amazon Web Services (d’ora in poi AWS) ha, come prodotto principe, EC2, un complesso e articolato sistema di erogazione di macchine virtuali on-demand con una vasta scelta di sistemi operativi e applicazioni eventualmente pre-installate.
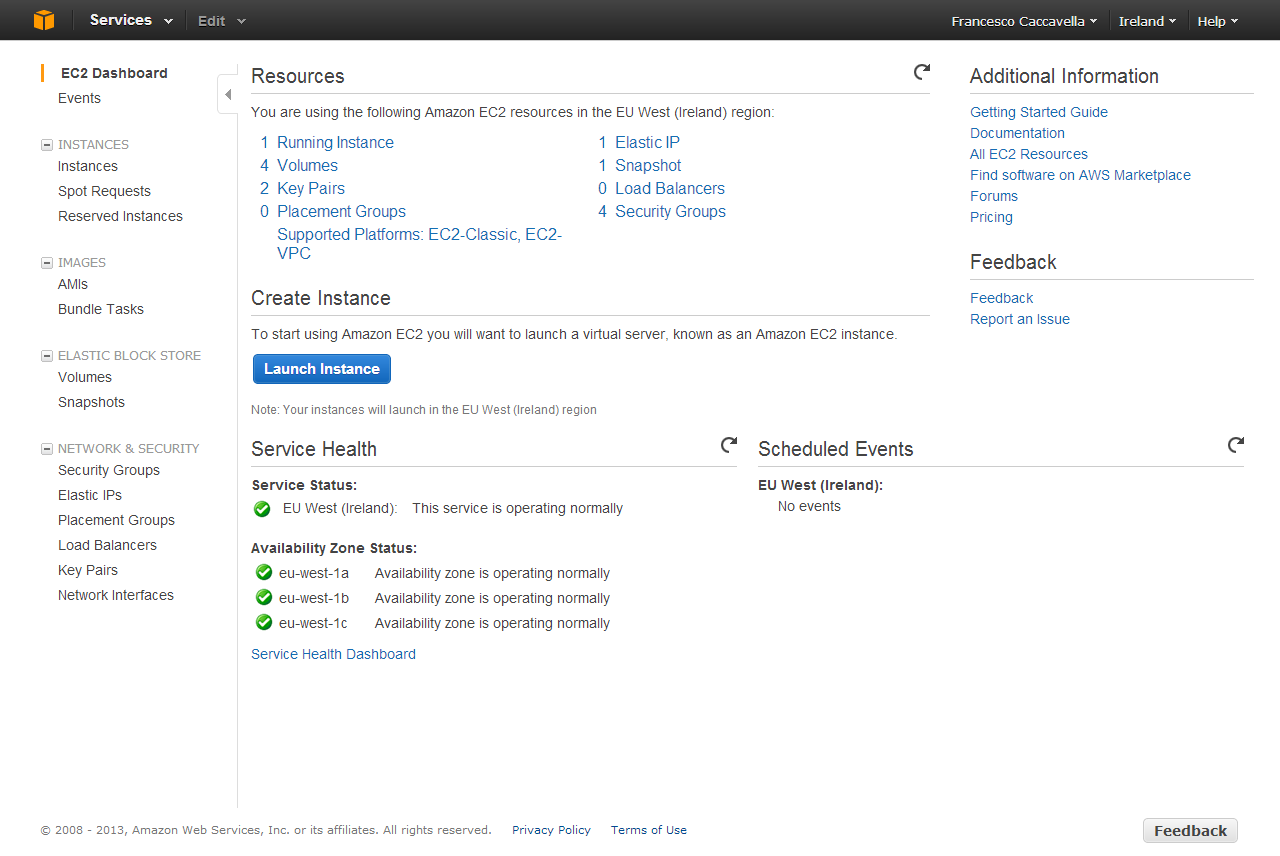
La complessità del servizio offerto impone un approccio analitico ai componenti del servizio, che riassumo in questa lista (rigorosamente in lingua inglese):
- Standard Instances
- Reserved Instances
- Spot Instances
- AMIs (Amazon Machine Images)
- Volumes
- Snapshots
- Security Groups
- Elastic IPs
- Placement Groups
- Load Balancers
- Key Pairs
In questo articolo analizzeremo ogni aspetto del servizio EC2 partendo, tuttavia, dal fondo della lista precedente per comporre piano piano l’ecosistema EC2 nella sua totalità. Affrontare prima i servizi “di contorno” serve infatti per comprendere meglio il servizio EC2 ed analizzarne gli aspetti.
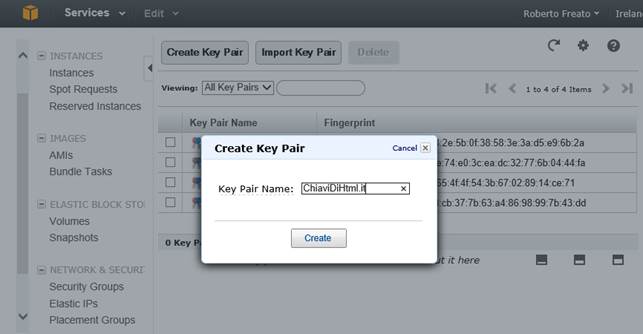
Key Pairs
Alcune operazioni di EC2 coinvolgono lo scambio di dati sensibili. Il primo scambio a cui ci troveremo di fronte, nel caso di creazione di una istanza Windows, sarà la richiesta della credenziale di amministrazione (si noti che i termini server, istanza o macchina saranno usati come sinonimo). Oppure nel caso della generazione di una macchina Linux, molto spesso la chiave privata dell’utente funge essa stessa da certificato di autenticazione su SSH. Il consiglio è di creare sempre una coppia di chiavi prima di ogni altra operazione, ed affidare ad essa un compito ben definito.
Ad esempio, se abbiamo 10 server sotto la nostra amministrazione, sarà comodo avere una sola coppia di chiavi per tutti e 10. Se al contrario, dovremo generare una istanza da affidare ad altri, potrebbe essere sbagliato utilizzare la nostra coppia di chiavi personale. Ogni qualvolta un server viene creato, ad esso viene associata una coppia di chiavi, motivo per cui è importante averne un paio pronto all’uso (anche se è possibile crearne una coppia “al volo” durante la generazione di una istanza).
Placement groups
Quando si ha a che fare con istanze ad alto potenziale (definiremo poi i tipi di istanze) è tipico uno scenario in cui esse devono avere, tra esse stesse, canali di comunicazione molto veloci e a bassa latenza. Ecco perché entra in gioco il concetto di Placement Group, come raggruppamento logico di istanze nella stessa “area” di datacenter, ad indicare che le istanze in esso avranno affinità reciproca.
Un’istanza tipo per cui ha senso parlare di Placement Group è la cc2.8xlarge che, interpretando la nomenclatura di AWS, è una ClusterCompute (cc) con 8 core fisici (8xlarge). Le cc2 hanno inoltre la peculiarità di avere Hyper-Threading e quindi 16 threads (core logici).
Creazione di istanze: AMIs
Creare istanze in AWS è una pratica che può essere molto breve o molto impegnativa, a seconda della topologia che vogliamo creare. Ogni azione che compiamo sul portale di AWS, previa attivazione di una sottoscrizione al servizio, può essere in realtà eseguita tramite console e/o genericamente automatizzata tramite i comandi che AWS espone sotto forma di chiamate HTTP.
Se si vuole creare una istanza da zero, ci si può affidare, dopo aver eseguito il login sul
ed aver selezionato la voce EC2 dalla lista dei servizi, al wizard che si attiva dal pulsante Launch Instance.
Interfaccia
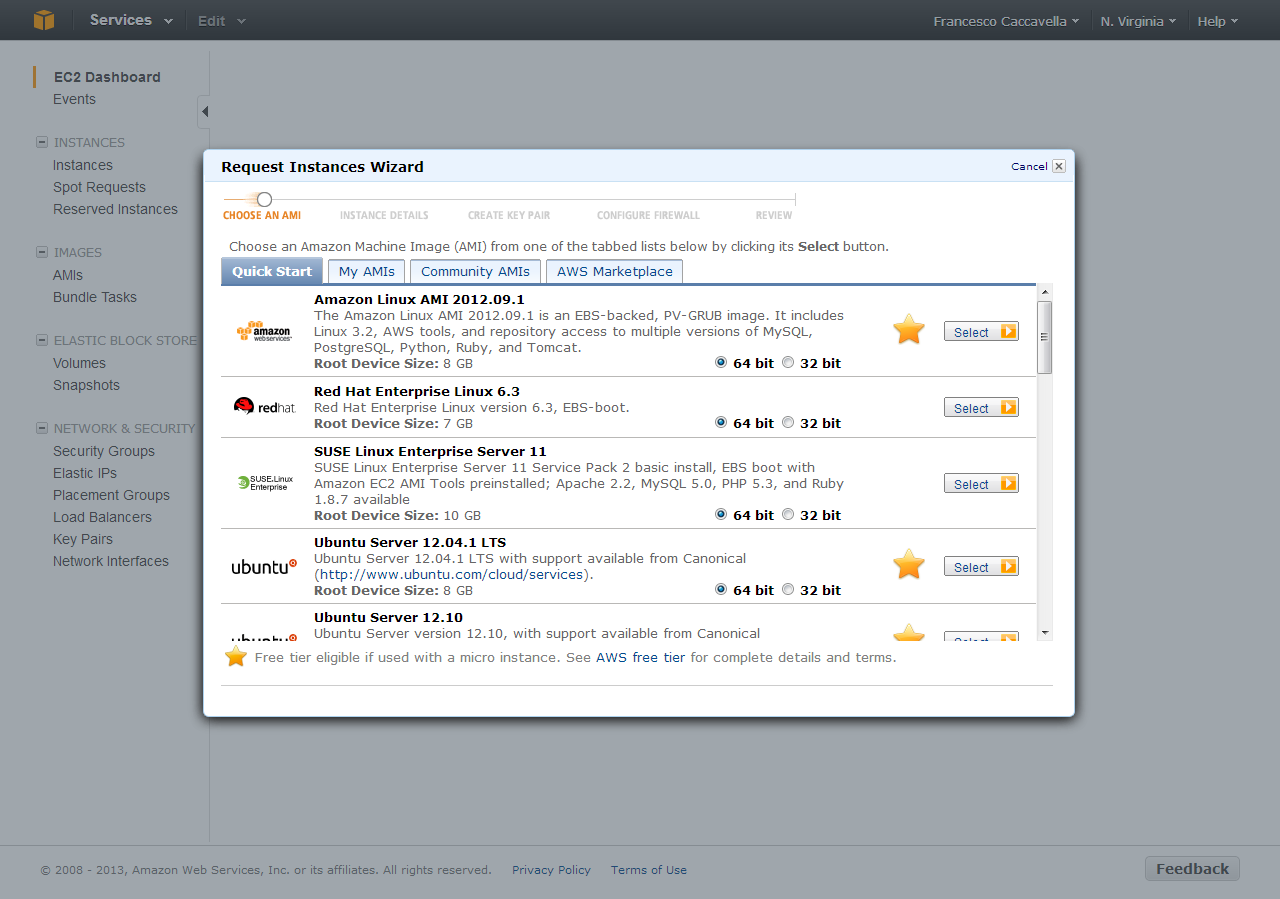
All’inizio dovremo scegliere quale AMIs (Amazon Machine Images) vogliamo applicare alla nostra istanza, cercando di ragionare il più possibile come se fossimo davanti ad un hyper-visor molto evoluto. Il primo passo è infatti indicare ad AWS quale sistema operativo lanciare sull’istanza, scegliendo tra una serie di immagini pre-confezionate da Amazon, oppure una miriade di immagini di terze parti create da aziende e/o genericamente dalla community di AWS.
La scelta dell’AMI è una scelta chiave: incide infatti sui costi (un server Windows costa di più di un server Linux) e, chiaramente, una volta avviata l’istanza non si può cambiare sistema operativo. Amazon inoltre fornisce una decina di possibilità di scelta di AMI da cui partire, mettendo a disposizione alcune combinazioni di software preinstallato ad alto valore aggiunto.
È disponibile infatti una immagine Windows Server 2008 R2 con SQL Server Express e IIS; oppure una immagine Windows Server 2012 con SQL Server Standard. In particolare il secondo caso risulta molto interessante perché, essendo in presenza di un componente server da costo di licenza non trascurabile, AWS lo fornisce “a consumo” e tariffando l’utente con una base oraria maggiorata proprio per comprendere il costo di licenza di SQL Server, spalmato quindi lungo l’asse del tempo piuttosto che facente parte dei costi di acquisizione.
Un’altra opzione è scegliere una istanza messa a disposizione dalla community: è il caso dei popolari stack pre-configurati, come quello di Bitnami, che forniscono immagini di istanze su Amazon AWS per coloro avessero bisogno velocemente di uno stack applicativo. Se per esempio avessimo bisogno del popolare WordPress, con tanto di MySQL, PHP e tutto l’occorrente, potremmo capire a quale codice di AMI corrisponda questo stack (nel caso di Bitnami, sul sito bitnami.org/stack/wordpress) per poi lanciare una istanza con quella AMI e ritrovarci qualche minuto dopo una macchina pronta all’utilizzo.
Infine, esattamente sullo stesso principio, alcune società terze possono mettere a disposizione una loro AMI con tanto di loro servizio/applicazione a pagamento (esattamente come nel caso SQL Server), fornendo quindi una istanza pre-configurata il cui costo orario sarà però maggiorato arbitrariamente. Un esempio popolare è lo stack di Adobe Media Server, una AMI pronta all’utilizzo che include nei costi orari il costo di licenza del prodotto server.
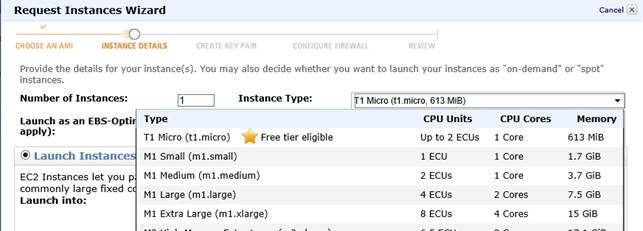
Una volta scelta la tipologia di istanza, si può scegliere dimensione e quantità: la prima indica le caratteristiche della macchina virtuale (secondo la lunga lista spiegata sopra); la seconda indica quante istanze identiche dobbiamo lanciare.
Infine c’è da creare Key Pair e Security Group ma, se li abbiamo già creati, basterà selezionarli da un menu a tendina. A conferma effettuata, AWS avvierà il lancio delle istanze e, dopo pochi minuti, avremo a disposizione delle istanze a cui connetterci.
Istanze Stateless vs Stateful
Spesso, trattando le architetture distribuite e più in particolare quelle Cloud-oriented, si sente parlare di Tier Stateless: i Web Tier o i Web Server sono spesso indicati nei documenti di architettura come server stateless e non tutti ne comprendono il motivo.
Questo motivo è legato alla natura di HTTP, il protocollo su cui la maggior parte delle applicazioni web oggi in circolazione poggia. In HTTP, ogni connessione (TCP) al server si apre e si chiude rispettivamente in fase di richiesta e in fase di risposta: ciò significa che il server non mantiene lo stato della connessione e, di conseguenza, non “riconosce” il client che gli ha fatto due richieste successive (tale identificazione deve avvenire lato applicazione, tramite la sessione del browser, i cookies o l’url). Questo principio rende un server web molto “sostituibile” ovvero, ipotizziamo che una prima richiesta la gestisca un server A, poi in un lasso di tempo molto breve sostituiamo il server A con un server B identico e facciamo in modo che possa stare in ascolto delle richieste HTTP che prima arrivavano ad A. In teoria il client non dovrebbe accorgersi di nulla a patto che lo “stato” del server sia sempre esternalizzato in una qualche sorgente dati esterna al server stesso.
Se infatti una prima richiesta al server A fosse relativa all’azione “salva la lista della spesa”, e questo salvataggio occorresse sul disco o nella memoria del server A, alla sua sostituzione con il server B una richiesta successiva di reperimento di quel dato non riuscirebbe ad essere soddisfatta. Per questo si dice che lo stato di un Web Server, quando questo web server debba essere sostituito o affiancato (vedesi Load Balancers), deve essere esternalizzato da qualche parte.
In queste condizioni si dice che il Web Server è stateless, ovvero che non gestendo internamente lo stato dell’applicazione, esso può essere sostituito senza che la logica dell’applicazione venga minimamente impattata.
Un server stateful è invece un server per il quale questa logica non è necessaria oppure semplicemente non si può ottenere: si rammenti però che la gestione di un server stateless è molto meno onerosa di quella di un server stateful, proprio per le caratteristiche di sostituibilità appena viste.
Load Balancers
Nell’ottica di avere una architettura che preveda una o più macchine che possano essere l’una la sostituta dell’altra o, ancora meglio, una in bilanciamento del carico dell’altra, è necessario dapprima che esse siano stateless e poi è necessario un componente noto come Load Balancer (bilanciatore del traffico). Il Load Balancer in AWS viene creato specificando alcuni parametri:
- Le istanze che fanno parte del pool di bilanciamento
- Come scegliere l’istanza migliore
I primo punto è banale mentre il secondo ha una serie di fattori da personalizzare, che di solito rispondono a queste domande:
- Voglio bilanciare il numero di richieste
- Voglio bilanciare il carico di computazione
Nel primo caso di parla spesso di bilanciatori round-robin, molto banali nella realizzazione quanto di semplice comprensione. Nel secondo caso, per stabilire la “salute” di una istanza del pool, bisogna in qualche modo far sì che il bilanciatore “chieda” e si informi di continuo su questo stato di salute.
In AWS, questa procedura di probing si può parametrizzare: basterà dire al bilanciatore di effettuare una connessione (HTTP/TCP) alle macchine e, in base ai timeout di risposta, stabilirne lo stato di disponibilità e di salute.
Nella figura qui in basso abbiamo creato un Load Balancer che dichiara un’istanza non più “in salute” quando non risponde (Unhealthy Threshold) a due controlli consecutivi che vengono eseguiti ogni 30 secondi (Health Check Interval) e per i quali si attende una risposta entro 5 secondi (Response Timeout). L’istanza sarà di nuovo segnata come “in salute” quando risponderà a 10 controlli (Healthy Threshold) secondo gli stessi tempi indicati sopra.
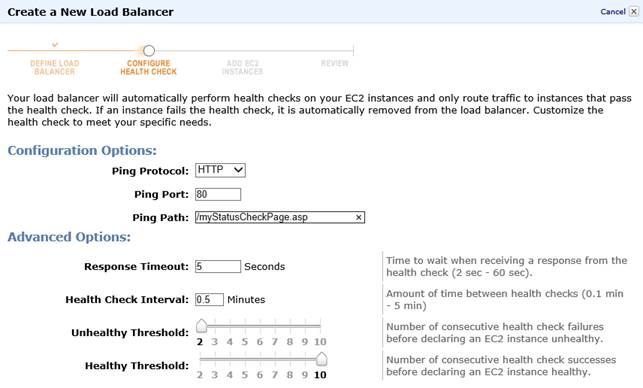
Una volta creato un bilanciatore, AWS ci assegna un nome DNS a cui esso risponderà, spesso nella forma: [nome]-[codice].[regione].elb.amazonaws.com. Questo nome DNS punterà, per ogni singola richiesta, ad una e una sola istanza alla volta, ciclando sul pool delle istanze “in salute”. Per associare al tipico nome di dominio www.miodominio.it il bilanciatore, occorrerà creare un record DNS di tipo CNAME che punti al nome sopra, lasciando ad Amazon la scelta dell’IP che gestirà fisicamente la richiesta.
Elastic IPs
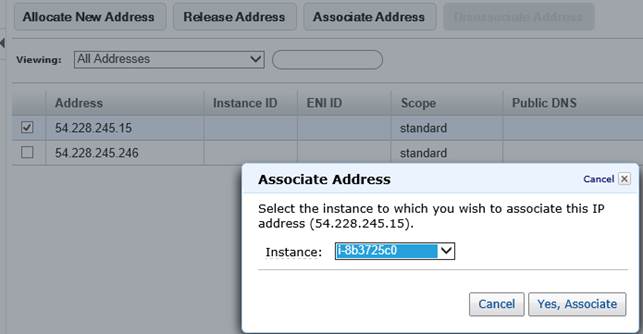
Abbiamo visto come creare istanze e, eventualmente, come metterle in bilanciamento attraverso un Load Balancer. Non sempre però è necessaria una topologia del genere, anzi molto spesso si vogliono ottenere macchine stand-alone e stateful. In questo caso, per poterci comunicare, è necessario un indirizzo IP e AWS permette di crearne uno o N al volo in modo elastico.
La creazione di un IP è banale e la sua associazione ad una istanza EC2 lo è altrettanto. Ciò che si suggerisce tuttavia, è di prestare attenzione a non richiedere IP senza associarli a della macchine EC2 (a meno che non lo si desideri esplicitamente): AWS infatti concede IP gratuitamente per tutto il tempo in cui essi sono associati ad istanze EC2 (che vengono infatti normalmente tariffate), applicando invece una tariffa per tutte le ore in cui essi sono allocati ma non assegnati.
Volumi EBS e storage transiente (o transitorio)
Nelle definizioni delle istanze (sopra) abbiamo visto come spesso, nel dettaglio delle caratteristiche offerte, compare lo storage fisico su disco, associato però alla parola “transiente”. Esso infatti è un particolare tipo di storage che ha vita solo ed esclusivamente fintanto che l’istanza è attiva/accesa e viene resettato nel momento in cui l’istanza viene stoppata (è, appunto, uno storage transitorio e temporaneo).
Un piccolo richiamo al ciclo di vita di una istanza AWS con storage transiente:
- Un utente lancia una istanza EC2 con storage transiente (instance-store)
- Viene prelevata l’AMI dall’archivio Amazon e viene agganciata dall’istanza
- Viene fatto eseguire il bootstrap e tutte le scritture da lì in poi (ovvero il differenziale tra l’immagine di partenza e le successive modifiche) vanno su uno storage temporaneo gestito da Amazon.
- Tutte queste modifiche vengono perse irrimediabilmente al verificarsi di una di queste condizioni:
- La macchina viene terminata dalla GUI
- La macchina subisce un crash e termina
- Dentro la macchina si invoca uno shutdown
EBS (Elastic Block Storage) è invece un servizio che permette di allocare volumi di spazio variabile, da associare poi ad una istanza in esecuzione. Questo genere di storage è invece persistente può essere esso stesso il disco di avvio di una istanza EC2
Per salvare contenuto statico per il web esistono infatti altri servizi, così come per lo storage NoSQL, e così via. Il primo beneficio immediato di una istanza EBS-backed è che essa può essere stoppata o terminata, preservando i dati della macchina, che quindi può essere riavviata in un futuro esattamente come se fosse a nostra disposizione. Le conseguenze sulle tariffe saltano subito all’occhio: se lo storage transiente è gratuito (nei limiti di istanza), quello EBS è a pagamento, ma permette di spegnere le istanze ove non servano con un eventuale risparmio sul costo stesso di computazione.
Un altro notevole vantaggio di EBS è che i volumi possono essere facilmente messi in backup con il servizio di snapshot, che tratteremo a seguire. Esistono quindi queste possibilità da considerare:
- Istanza Linux con solo il disco di avvio instance-store
- Istanza Linux con disco di avvio instance-store e dischi aggiuntivi a pagamento EBS
- Istanza Linux con soli dischi istance-store
- Istanza Linux/Windows con disco di avvio EBS e dischi aggiuntivi instance-store
- Istanza Linux/Windows con disco di avvio EBS e dischi aggiuntivi EBS
Nell’elenco notiamo che le combinazioni che coinvolgono il disco di avvio in modalità instance-store non sono disponibili per Windows: questo è dovuto al fatto che Windows ha bisogno di un disco di avvio di almeno 30GB
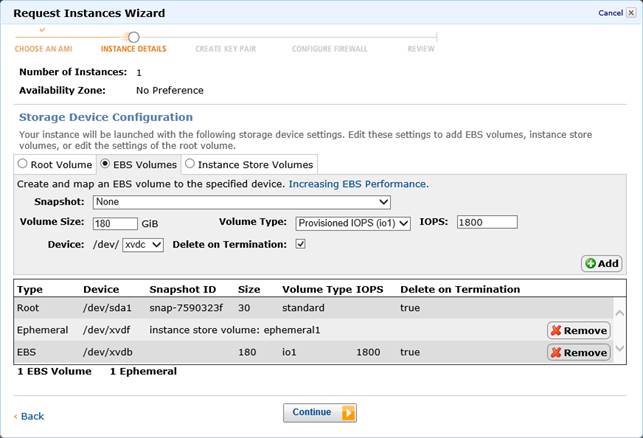
Provisioned IOPS
I volumi EBS riescono a fornire performance pari a circa 100 IOPS di media, con un basso costo ed una affidabilità non massima. Nel caso si vogliano ottenere prestazioni maggiori, ma soprattutto una predicibilità delle stesse (ad esempio per applicazioni database), è possibile utilizzare i volumi EBS con IOPS a scelta dell’utente. Inoltre, dato che al momento AWS supporta IOPS custom fino a 2000 per volume, l’utente è libero di creare N volumi da mettere in serie (striping) in modo da ottenere IOPS arbitrarie.
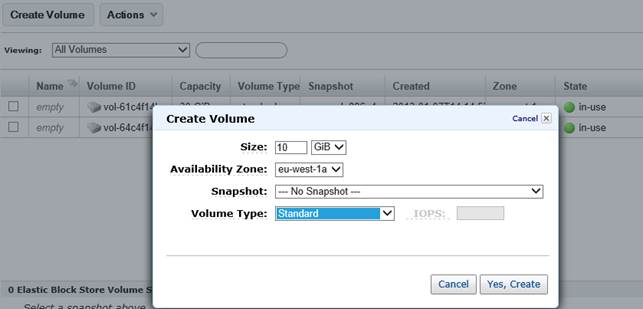
Snapshot
Gli snapshot sono uno strumento molto potente che mette a contatto l’utente con il sistema di virtualizzazione di Amazon. Infatti, con il termine snapshot, si identifica spesso quel processo per cui, data una risorsa virtuale, se ne scatta una istantanea allo scopo di utilizzarla in seguito ai fini di restore (applicativo o per disaster recovery). Ogni hypervisor ha regole proprie e in Amazon i backup EBS funzionano così:
- Un volume EBS può essere creato da zero (quindi sarà vuoto) oppure partendo da uno snapshot e/o da una AMI di AWS o di terze parti (in tal caso conterrà dei dati iniziali).
- In entrambi i casi, il processo di snapshot crea un archivio (lo snapshot, appunto) con i soli file differenziali tra l’ultimo snapshot (nel caso di AMI) o l’immagine vuota.
Questo comportamento fa sì che il backup sarà solo il differenziale tra l’ultimo backup e lo stato attuale
Gli snapshot, una volta creati, possono essere condivisi con la community o con determinati utenti e da essi è possibile ricavare una AMI custom da utilizzare in seguito o da condividere anch’essa con l’esterno: è inoltre possibile copiare lo snapshot in differenti regioni AWS.
Restore
Il processo di restore di uno snapshot prevede la creazione del volume EBS originario. Relativamente agli spazi di memorizzazione occupati, lo snapshot viene fatto comprimendo il disco EBS in modo da salvare solo lo spazio occupato (in modo incrementale, come abbiamo visto sopra), mentre il volume EBS consuma sempre la quantità di spazio pari alla sua dimensione massima (anche se poi è effettivamente parzialmente riempito).
Il restore di uno snapshot crea un volume EBS i cui dati sono caricati al volo, al momento della richiesta. Ciò significa che un volume EBS creato a partire da uno snapshot è subito disponibile, ma i suoi dati verranno prelevati da S3 solo nel momento il cui il sistema operativo ne chiederà la disponibilità (ovvero li leggerà). Questo processo, noto come lazy-loading, incrementa di molto le performance di avvio delle nuove istanze.
Le immagini: AMIs
Creare una immagine è un processo molto utile per diverse necessità:
- Avere un sistema operativo di base con pre-installate una serie di utilities e di applicazioni.
- Creare macchine stateless pre-configurate, al fine di poterle accendere on-demand.
- Condividere una macchina tra utenti diversi
Questo processo può essere applicato sia alle istanze con storage transiente (si parlerà di Bundle instance), sia alle istanze EBS-backed (si palerà in tal caso di EBS AMI). Il processo di creazione di una AMI merita un articolo a sé, per cui riassumiamo solo i punti salienti, partendo da questi due casi:
- L’utente crea una macchina che personalizza con le proprie impostazioni
- L’utente ha uno snapshot di un volume EBS
Il processo di creazione dell’AMI EBS
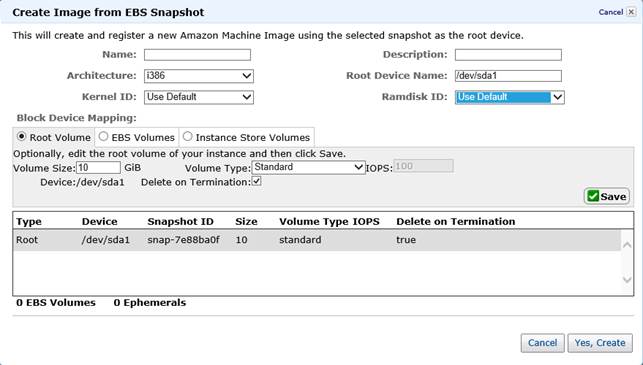
Reserved Instances
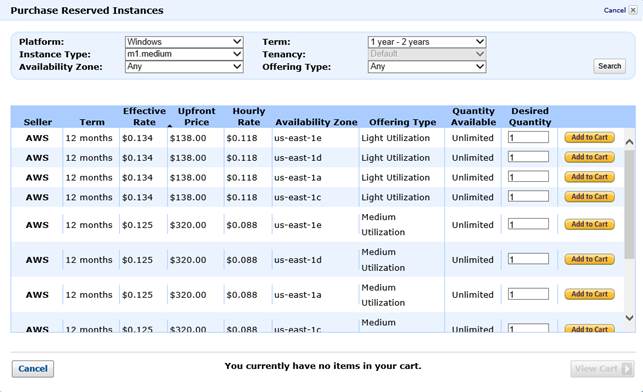
Non sempre il modello pay-per-use può essere ciò che si cerca, soprattutto quando si ha a che fare con un minimo di servizio sempre da garantire al nostro utente finale. In questi casi, è facile calcolare che una istanza AWS, seppure piccola, può costare molto di più di un suo corrispettivo presso una qualsiasi società che offre servizi di hosting. Sappiamo bene che con il Cloud Computing possiamo scalare in modo elastico e aggiungere risorse on-demand ma, se abbiamo bisogno di N istanze comunque sempre accese, potremmo trovare convenienza ad andare altrove.
Per questo entra in gioco il concetto di istanza riservata: con un anticipo proporzionale alla dimensione dell’istanza che vogliamo tenere sempre accesa e al termine temporale di questo “impegno”, la tariffa oraria viene ridotta drasticamente con un notevole risparmio anche sul lungo periodo. Senza utilizzare le cifre ufficiali (per via del fatto che sono soggette a cambiamenti periodici), mostro un esempio tipico:
- On-demand puro
- Costo orario di istanza di dimensione A: 10cent
- Istanza riservata (on-demand con anticipo)
- Anticipo: 100
- Costo orario di istanza di dimensione A: 5cent
Si fa presto a capire che nel primo caso, un anno di esecuzione, ci costa 876; nel secondo caso invece, il costo si abbatterebbe a 538 (considerando sia l’anticipo che il consumo orario decurtato). Una istanza si può riservare relativamente ad un datacenter specifico e per un lasso di tempo compreso tra 1 mese e 3 anni. Ovviamente i prezzi cambiano se trattiamo un server Windows e/o con server su cui sono presenti software a licenza.
Spot Instances
Le istanze spot rappresentano un concetto molto complesso per chi si appresti per la prima volta ad utilizzare un fornitore di IaaS. Per comprendere cosa stiamo per affrontare, pensiamo al concetto di macchina stateless. Come si diceva sopra, una macchina è stateless quando non mantiene lo stato dell’applicazione (e quindi lo esternalizza) in modo da rendersi completamente sostituibile e/o affiancabile in un pool di istanze (per esempio per stare “dietro” ad un Load Balancer).
In questa circostanza, aumentare il nostro pool o diminuirlo dovrebbe essere una operazione da pochi secondi, giusto il tempo di cliccare da qualche parte sull’ipotetico bottone “+1/-1”. In queste condizioni, in cui la governance dei nuovi server è completamente automatizzata (si pensi ad un sistema di auto-scaling che reagisca alle oscillazioni di traffico per allocare/deallocare server), si potrebbe pensare di intervenire sull'algoritmo di allocazione/deallocazione, per esempio imponendo vincoli di costo.
Ad esempio l’azienda A potrebbe avere una topologia con 2 server di base e un algoritmo di auto-scaling che scali fino a 10 server liberamente, dopodichè avvisi un amministratore che c’è bisogno di più computazione. Di solito si pensa ad un tetto massimo di scaling per motivi di costo: è infatti comune pensare che, un qualsiasi attacco e/o errore di progettazione potrebbe far schizzare a numeri elevatissimi il conto dei server attivi, con conseguenze drammatiche sulle fatture mensili.
In questo scenario, discretamente complesso, potrebbe essere utile la Spot Instance: il meccanismo di AWS permette di richiedere il lancio di nuove istanze (anche a partire da AMI custom) se e solo se il “prezzo di mercato” di tali istanze in quel momento è inferiore ad una soglia prestabilita. Questo “prezzo di mercato” è un prezzo impostato da AWS e che varia in base all'effettiva richiesta di quel tipo di istanza in un dato momento.
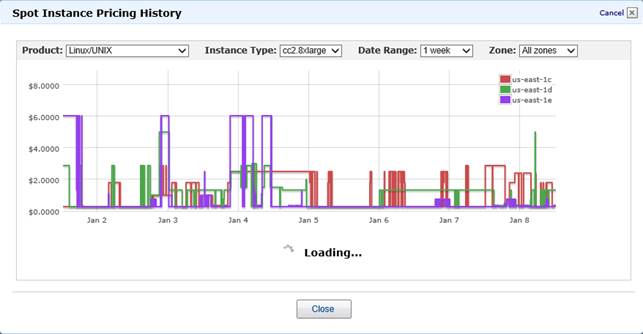
Il meccanismo, analogo a quello della borsa valori, permette di plasmare in modo elastico una architettura con N istanze sempre attive, M allocabili dinamicamente e K allocabili dinamicamente se e solo se di costo inferiore al nostro massimo stabilito. Infine, perché è necessario che le nostre macchine spot siano stateless? Perché AWS, nel caso il prezzo di mercato superi la soglia che abbiamo impostato, distruggerà immediatamente la macchina.
Figura 12 - Impostazone delle regole di bid per le istanze spot.
TCA vs TCO
I fornitori di servizi Cloud Computing (SaaS, PaaS e IaaS), come detto in precedenza, devono sottostare almeno a due semplici regole: fornire risorse on-demand e tariffarle a consumo. Questo paradigma, contro ogni logica dei “canoni” o dei “contratti” mensili/annuali, rende il calcolo del costo di un servizio da un lato molto complesso (bisogna fare un mix dei vari servizi utilizzati) dall’altro molto flessibile e con un TCO decisamente più predicibile. Il TCO è appunto il costo totale di possesso di una infrastruttura IT, considerando oltre al costo di acquisizione, quello di manutenzione, dei costi vivi (per esempio l’elettricità), del personale tecnico e della dismissione. In un sistema complesso è spesso altrettanto difficile stimare questi costi e spesso, sbagliando, si valutano esclusivamente i costi di acquisizione, ovvero il TCA.
Con un modello elastico le cose cambiano e, avendo la possibilità di interrompere in qualsiasi momento un servizio, la spesa sarà sempre e solo quella accumulata dall’istante iniziale all’istante corrente, con la sensazione di stare letteralmente “spalmando” il TCO giorno per giorno, anzi ora per ora.
Tariffe dei servizi
I prezzi dei servizi di Cloud Computing sono sempre soggetti a modifiche, visto il crescente numero di competitor sul mercato e visto l’abbassamento dei costi di produzione dell’hardware e delle economie di scala dei datacenter. Per questo il massimo che si può fare per riportare i costi di EC2, è fornire il link con i prezzi aggiornati, sempre reperibile su
.
Infine, le modalità di stima dei costi dello IaaS è un argomento da trattare separatamente, in quanto implica una già buona conoscenza dei servizi in gioco e di cosa si debba considerare quando si implementa una architettura cloud.
